install.packages(c("httr","jsonlite","xml2"))11 데이터 수집하기
조작화와 시각화가 ’보도’에 가깝다면, 이 장에서 배울 것은 ’취재’에 가깝습니다.
서두에서 이야기 한 것처럼, 데이터 저널리즘을 위한 데이터 수집법에는 여러가지가 있습니다:
- 검색: 공개 파일, 깃헙 등등
- 공여: 자발적/취재/정보공개청구
- 기자 그룹내 공유
- API
- 웹스크레이핑/크롤링
여기서 첫 번째 세 경우는 기존의 저널리즘에서 일반적으로 이루어지던 데이터를 찾는 방법이라고 하겠습니다. 데이터 저널리즘만의 특별한 기술이 필요한 것은 아니지요. 우리가 여기서 다룰 것은 네 번째, 다섯 번째 경우에 필요한 기술들입니다. 차차 설명하겠지만, API(Application Programming Interface)는 데이터를 보유한 측(주로 정부나 기업)에서 자신의 데이터를 가져가라고 만들어 놓은 공식적인 통로 또는 규칙을 의미라고 생각하면 좋겠습니다. 자신의 데이터를 남이 이용하는 것이 (여러 이유로) 필연적이라면, 허용된 정보를 질서있게 가져가도록 하는 규칙 같은 것이지요. 즉, API가 있는 경우는 첫 번째 세 경우처럼 거의 바로 분석 가능한 테이블 형태는 아니더라도, 데이터를 가지고 있는 측에서 나름대로 데이터를 가져갈 것을 예상하고 정리한 형태로 주는 경우 입니다. 따라서 데이터의 규칙이 분명하고, 그 규칙을 이용해 데이터를 다운 받고 분석 가능한 형태로 만드는 기술을 익히면 됩니다. 추가적인 공부가 필요하지만, 그래도 나쁘지 않은 경우라고 할 수 있지요.
웹스크레이핑 또는 크롤링을 해야 하는 경우는 조금 더 복잡합니다. 데이터를 가지고 있는 측에서 자발적으로는 데이터를 줄 생각이 없거나, 또는 그것을 꺼려하는 경우이지요. 이 경우에는 대상이 되는 홈페이지 또는 데이터베이스의 구조와 작동방식을 알아내는 일종의 역설계(reverse-engineering) 과정이 필요합니다. 데이터가 어떻게 저장되고 공개되는지를 알면 그것을 역이용해서 자동화된 프로그램을 만들어 데이터를 얻어내는 스크레이핑 또는 크롤링을 할 ‘수도 있기’ 때문이지요. 물론 이를 기술적으로 법적으로 막기도 합니다. 이 경우는 훨씬 더 많은 기술과 지식을 필요로 합니다. 왜냐하면 API와 달리 개별 홈페이지, 데이터베이스는 작동하는 방식이 각각이기 때문에 그를 공략하는 프로그램 역시 경우에 따라 다 달라야 하기 때문이지요. 사실 이것마저 기자 개인이 마스터하기는 쉽지 않습니다. 따라서, 여기서는 웹스크레이핑을 위한 기초적인 지식과 가장 간단한 예만 다루고, 더 복잡한 작업을 ’의뢰’할 때 알아야 하는 기술 요소들에 대한 직관적인 설명만을 하겠습니다.
11.1 Web의 구조와 웹API의 기초
스크래이핑과 크롤링에 대해서는 간단하게만 언급한다고 하니 실망하는 분도 있겠지만, 사실 API를 통해 공개되어 있는 데이터만 이용할 수 있어도 이전에는 접근할 수 없었던 굉장히 방대한 양의 데이터에 접근하게 되는 것입니다. 아마도 최근 굉장히 많은 사적, 공적 정보들이 웹API라는 것을 통해서 공유된다는 이야기는 들어본 분도 있을 것입니다. 웹API가 무엇인지를 이야기함에 앞서, 도대체 왜 더 많은 데이터들이 웹API를 통해 공개되는 것일까요?
기업이나 공공기관이 자신이 보유한 데이터를 공유하는 이유는 적극적인 측면과 수동적인 측면으로 나누어 설명해 볼 수 있습니다. 적극적인 이유는 데이터를 공유함으로써 자신이 운영하고 있는 플랫폼에 더 많은 사람들을 참여시키는 것이 스스로의 이익과 부합하는 경우이지요. 투명한 정보 공개를 통해 행정에 대한 시민들의 참여를 늘리려고 하는 공공기관이 그런 경우 중 하나라고 할 수 있죠. 이렇게 투명한 행정은 정부가 스스로 원하는 경우도 있지만, 시민사회가 적극적으로 요구하는 경우가 늘어나고 있습니다. 기업의 경우에는 다른 기업이 자신이 보유한 플랫폼 위에서 플랫폼 이용자를 대상으로 다른 기업이 사업을 하도록 하고 싶은 경우가 그렇습니다. 페이스북, 유튜브와 같은 소셜 미디어를 생각해보면 알 수 있지요. 이러한 기업들은 이용자에 대해 알아낸 정보를 일부 광고주들에게 제공하면, 광고주들은 그덕분에 개별 이용자들에게 맞춤형 광고를 전달할 수 있습니다. 물론 그 댓가로 소셜미디어 기업들은 서비스의 품질을 올리고, 결과적으로 더 많은 이용자들을 끌어들일 수 있겠지요. 즉, 플랫폼 기업, 광고주, 이용자 간의 윈-윈을 통해 전체 비즈니스 생태계를 크게 만들려는 전략입니다.
물론, 웹API를 제공하지 않아도 특정 온라인 기업이 보유한 정보가 매우 매력적이라면, 개별 이용자나 다른 기업들이 해당 서비스에서 정보를 빼가기 위해 많은 노력을 하겠지요? 아마도 웹스크레이핑, 크롤링 등의 수단을 동원할 것입니다. 만약 많은 사람들이 무질서하게 정보를 가져가기 위한 노력을 하게 된다면 어떻게 될까요? 너무 많은 접속이 발생해 서비스가 느려지거나, 심지어 멈춰버릴 수도 있겠지요. 유명 가수의 콘서트 예약을 위해 많은 사람들이 한번에 접속하는 경우를 생각해 보세요. 또, 다른 개인 또는 기업과 공유하고 싶지 않은 정보를 무질서하게 가져가려 하는 경우도 발생하겠지요. 따라서 기업들은 기왕 자신의 정보를 공유할 것이라면, 자신들이 정해놓은 통로와 규칙에 따라, 서비스 질의 저하를 피하면서 공유하고 싶은 정보만 공유하는 전략을 취할 유인이 있습니다. 이것이 웹API를 통해 정보를 공유하는 수동적인 이유입니다.
그런데 애초에 API는 무엇일까요? 사실 여기서 이야기 하는 API는 웹API 입니다. 사실 API라 하면 소프트웨어와 다른 소프트웨어가 정보를 주고받을 수 있는 통로를 모두 포괄해서 이야기 하는 것이거든요. ’웹API’라고 하면 인터넷을 통해 서비스를 제공하는 소프트웨어(예컨대 인스타그램과 같은 소셜미디어)가 사람이 아닌 외부 소프트웨어에게 정보를 주는 규칙을 의미합니다. 사람에게 정보를 주는 화면을 UI(유저 인터페이스)라고 한다면, API는 소프트웨어에게 정보를 주는 방식이지요.
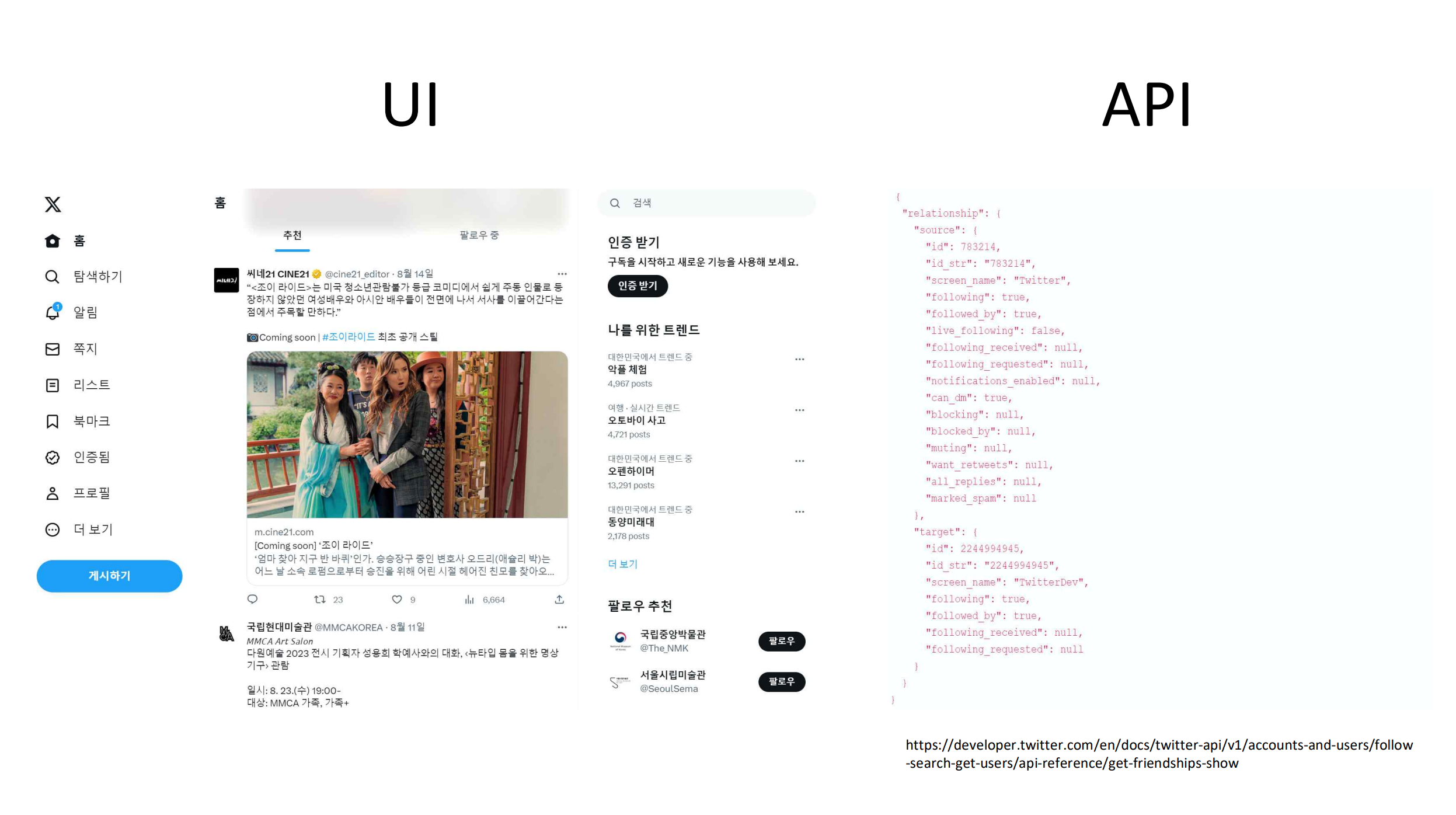
그런데 웹API는 너무도 자주 사용하기 때문에, 그 방식이 어느정도 표준화되어 있습니다. 때문에, 웹스크레이핑, 크롤링과 달리 그 표준을 사용하는데 필요한 몇가지 지식과 기술을 가지고 있으면 API를 통해 정보를 얻을 수 있는 것이지요. 이 표준을 이해/이용하는데 필요한 기술은 HTTP라는 통신 규약, 그리고 XML, JSON이라는 테이블과는 다른 데이터 형식이 전부입니다.
11.2 API 처음 경험하기: data.go.kr
이 교재에서는 대한민국 정부가 운용하는 공공데이터포털에서 제공하는 API를 사용할 것입니다. 공공데이터 포털은 관련 법령에 따라 국가행정기관에서 생성 및 관리하고 있는 데이터를 총 망라하여 파일 형태, 또는 API 형태로 제공합니다. 여기서 제공하는 데이터들은 그야말로 정책 입안을 위한 참고자료로 삼기위해 이루어진 조사 결과를 제공하는 통계청 국가통계포털과 성격이 다소 다릅니다. 통계청은 ‘한국노동패널조사’, ’사회통합실태조사’와 같은 국가 단위의 조사 결과를 공유한다면, 공공데이터포털에서 제공되는 데이터들은 실시간 대기 오염 정보, 아파트 실거래가 정보등, 조사를 위한 노력을 하지 않아도 저절로 만들어지는 데이터들 역시 포함합니다.
앞으로의 실습을 위해 먼저 공공데이터포털에 회원가입을 하시길 바랍니다. 그래야 API를 이용하기 위한 자격을 얻을 수 있습니다. 로그인 후, 첫 화면에서 ’한국환경공단_에어코리아_대기오염정보’라는 검색어로 검색을 해 보도록 합니다.
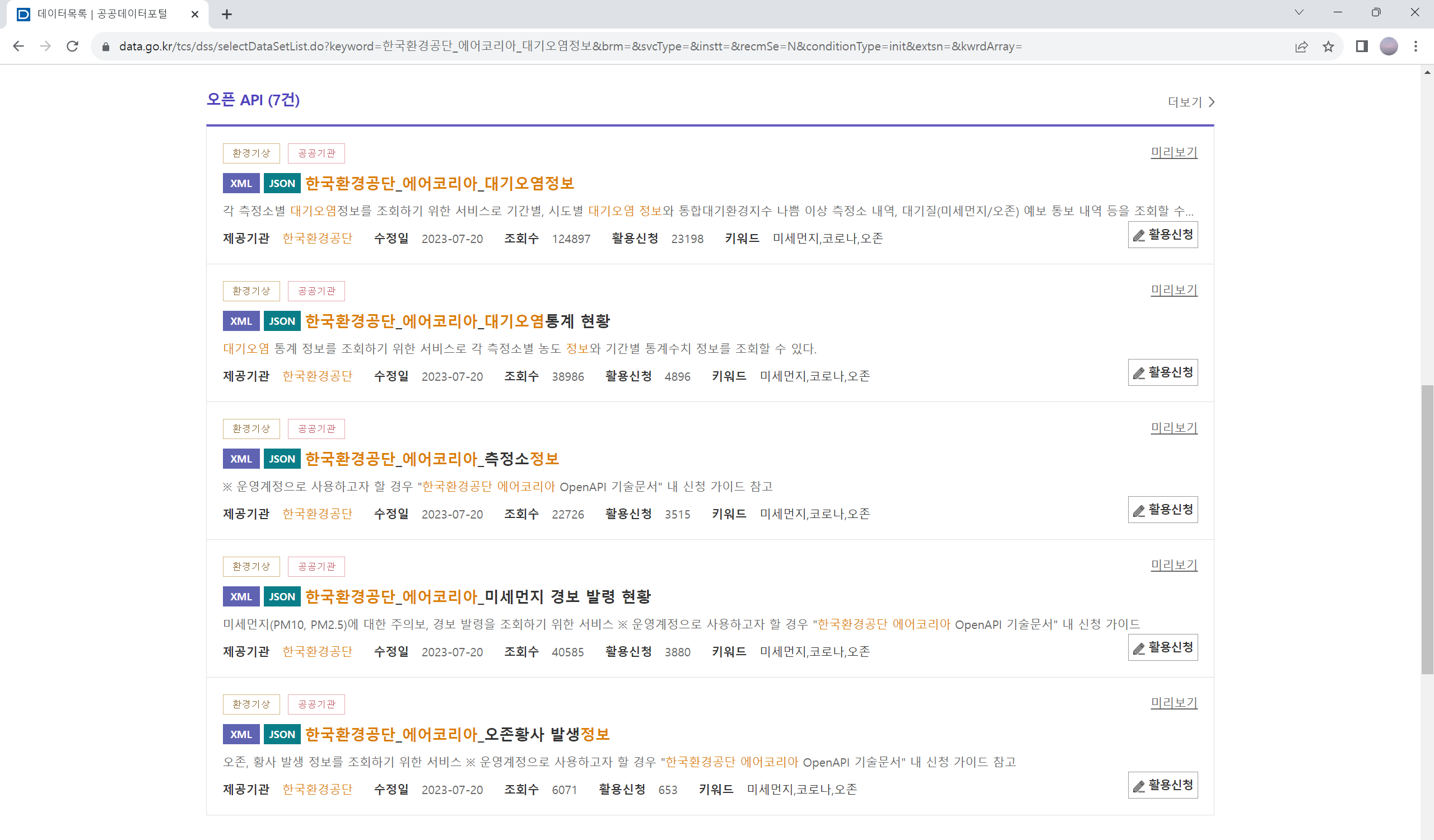
여기서 오픈API 항목 가장 위에 보이는 ’한국환경공단_에어코리아_대기오염정보’를 클릭 합니다.
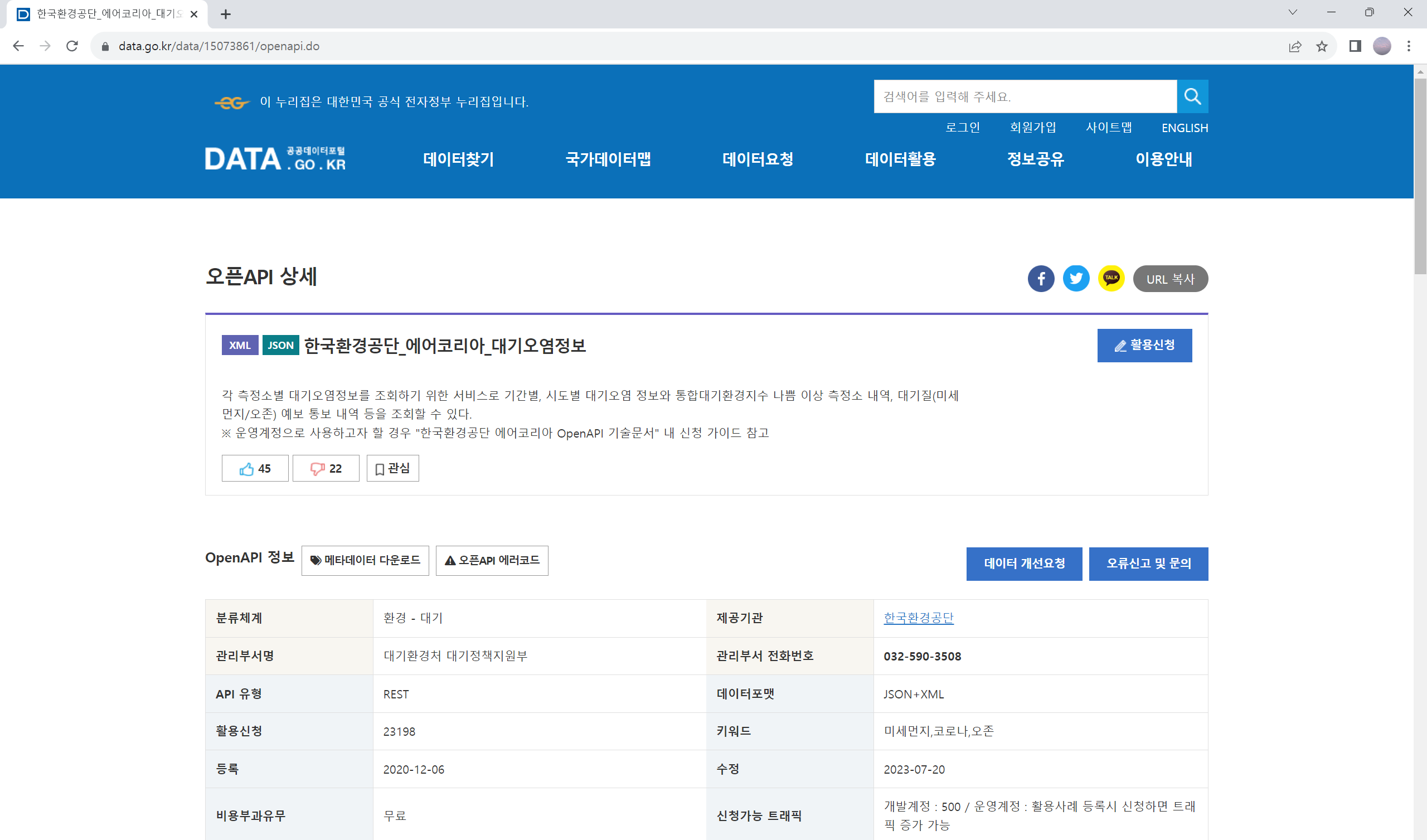
이제 ‘활용신청’을 클릭하면 다음과 같은 화면이 나옵니다. ’활용목적’ 부분을 적당히 기입하고, 라이선스에 동의한 후, 활용신청을 해 주세요. 그러면, ’활용신청 현황’이라는 화면이 뜨면서, 지금까지 여러분이 이용 신청을 한 API 목록이 나타납니다. 이 화면은 사실 주메뉴(화면 최상단)으로부터 ’마이페이지-> 데이터활용-> Open API -> 활용신청 현황’을 차례로 클릭해서 볼 수도 있습니다.
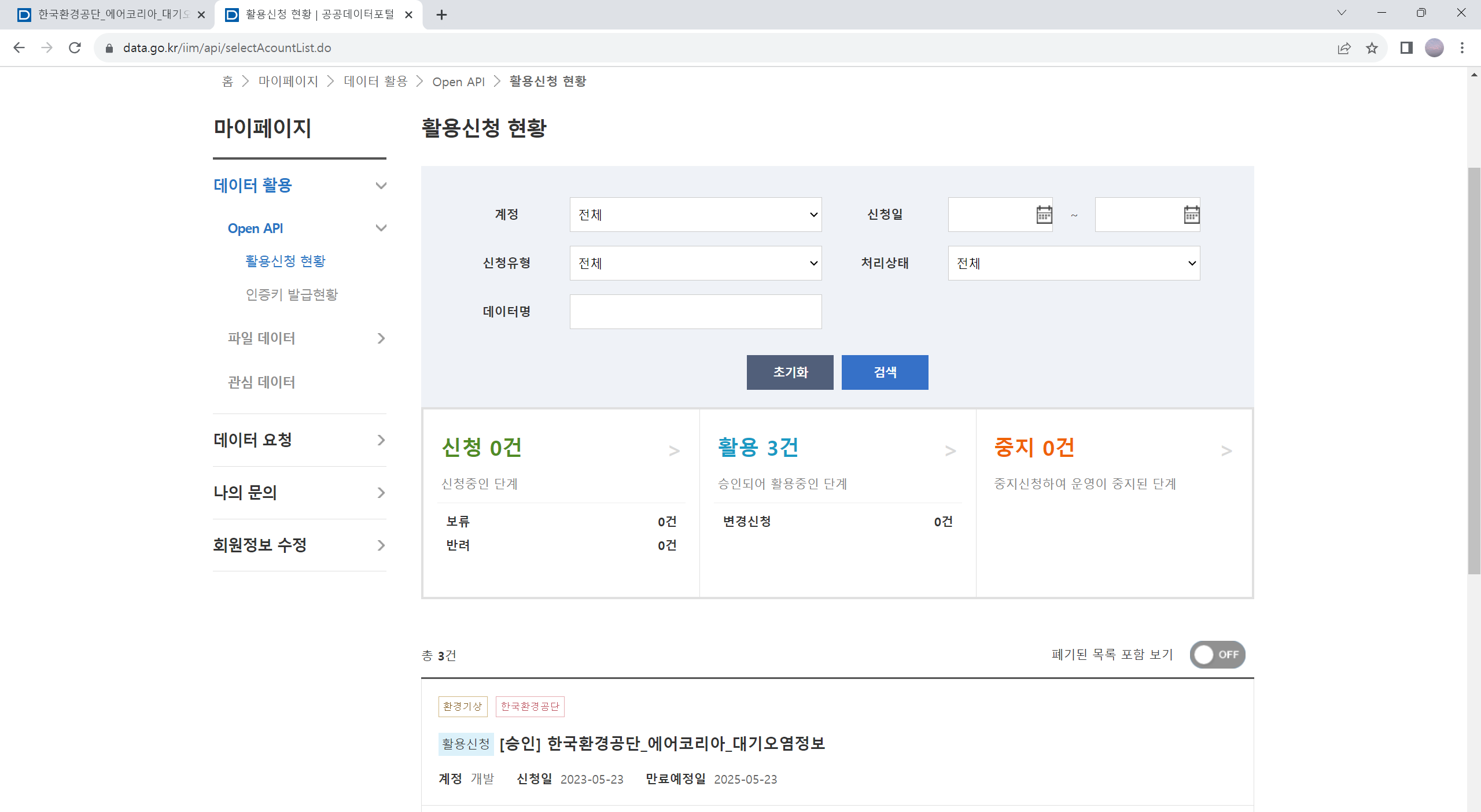
어떤 경우에는 이용 승인에 시간이 걸리는 경우도 있지만, 많은 경우 바로 승인이 되어 API 이름 앞에 ’[승인]’이라고 표시되어 있습니다. 만약 승인이 되었다면, 방금 신청한 API를 클릭해보세요. 그러면 다음과 같은 화면이 나타납니다.
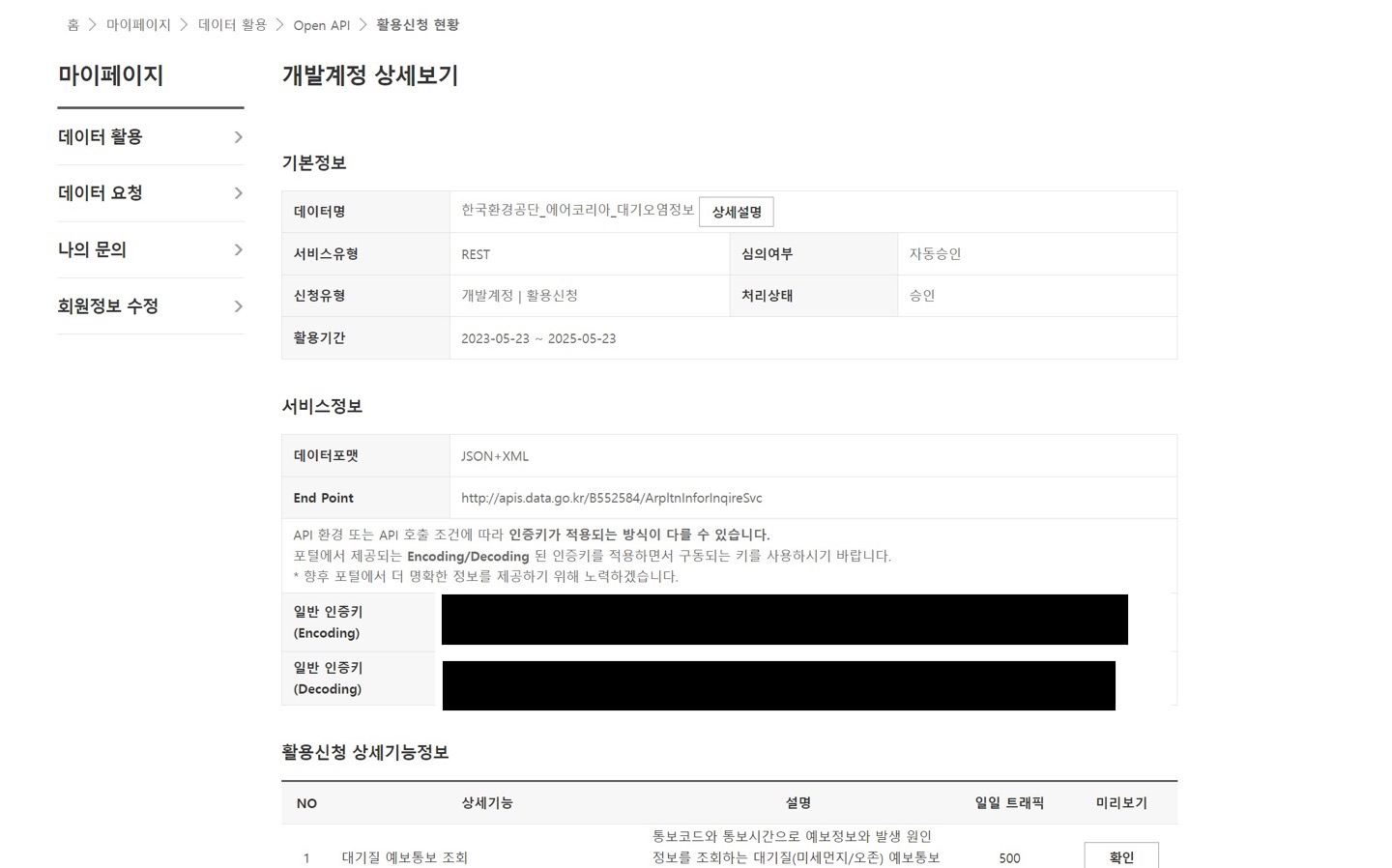
호 여기에는 해당 API와 관련된 여러 정보들이 설명되어 있지만, 가장 중요한 것은 ‘End Point’라고 표시되어 있는 API 주소와, 비밀번호에 해당하는 ’일반 인증키’ (Encoding버전, Decoding 버전 중 무엇을 쓰든 큰 상관이 없습니다) 입니다. 이 두 정보를 메모장 같은 곳에 잘 옮겨두세요. 그 다음, ‘데이터명’ 항목 옆에 있는 ’상세설명’을 클릭합니다. 그러면 다음과 같은 화면이 나타납니다.
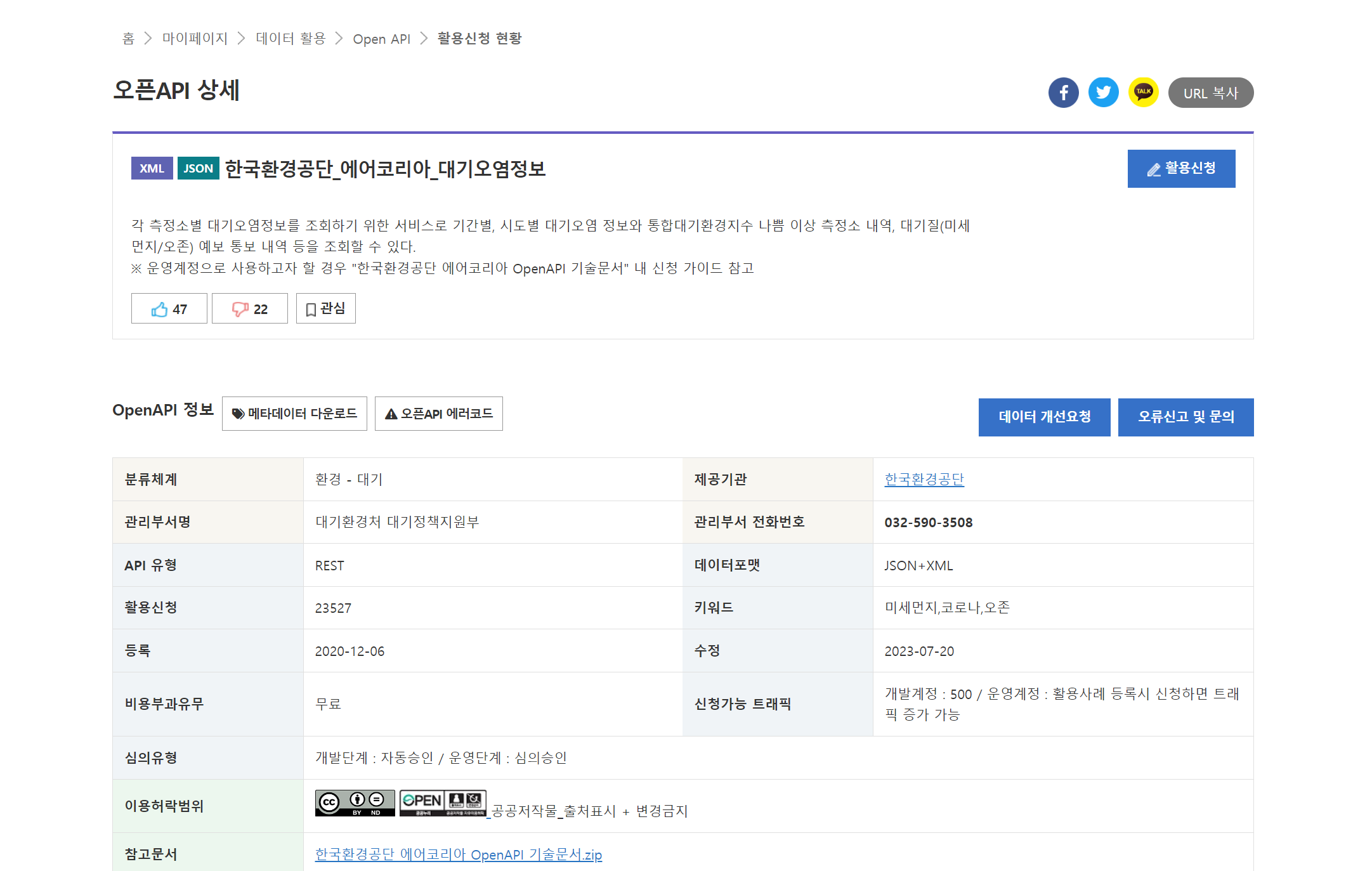
여기에는 API를 이용하는데 필요한 규칙이 대략적으로 기술되어 있습니다. 정확한 정보는 ‘참고문서’ 항목에서 다운받을 수 있는 메뉴얼에 자세하게 기술되어 있습니다. 시험삼아 한 번 열어 보세요. 처음에는 복잡해 보일지 몰라도, 정부에서 표준화한 형식을 따르고 있는 문서이기 때문에, 몇 번의 연습을 통해 익숙해지고 나면 다른 API를 이용할 때에도 이용법을 쉽게 이해할 수 있게 됩니다.
자, 이제 공공데이터포털에서 제공하는 API를 통해 데이터를 다운받을 준비가 끝났습니다. 이제 다시 R로 돌아가서 실제로 데이터를 다운받아 보도록 하겠습니다.
11.3 R을 이용해 API 이용하기 - 다운로드
여기서는 httr, jsonlite, xml2라는 패키지를 이용하게 될 것입니다. 앞서 API를 이용하기 위해서는 HTTP라는 웹 통신 규칙, JSON, XML이라는 데이터 형식을 이해하면 된다고 했지요? 이 3개의 패키지는 각각 HTTP, JSON, XML을 R에서 다루기 위한 기능을 제공합니다. 이러한 패키지들에 대해 처음 들어보신다면, 설치가 되어있지 않을 것이므로, 다음 코드를 통해 설치를 완료해주세요.
HTTP(Hyptertext Transfer Protocol)는 웹페이지에 대한 정보를 담고 있는 서버 컴퓨터와 이용자의 컴퓨터 사이에 정보를 교환하기 위한 규칙으로, 여러분들이 웹브라우저에서 ‘HTTP’ 또는 ’HTTPS’로 시작되는 웹페이지 주소를 사용할 때 늘 사용하고 있는 규칙입니다. 표준적인 웹API는 소프트웨어 사이에 정보를 주고받는데 바로 이 HTTP를 사용하기 때문에, R에서 웹API를 사용하려면 R이 브라우저 처럼 HTTP를 이용해 외부 컴퓨터와 정보를 주고 받게 해 주는 패키지, 즉, httr을 이용해야 하는 것입니다.
여느 패키지를 이용할 때처럼, 해당 패키지를 불러오도록 합시다.
library(tidyverse)
library(httr)HTTP가 작동하는 방식은 간단합니다. 서버 컴퓨터에게 규칙에 따라 특정 정보를 달라고 ’요청’하면, 서버가 이용자가 해당 정보를 볼 권한이 있는지, 요청한 정보가 있는지 확인한 후 그에 ’응답’합니다. 이러한 통신을 위해서는 다음 세 가지 정보가 필요합니다.
- 요청 메시지를 보낼 웹API의 주소
- 요청 권한이 있다는 것을 나타내는 인증키
- 원하는 정보를 서버가 정한 방식에 따라 요청하는 규칙
이 정보들은 모두 공공데이터포털 또는 앞서 내려받았던 메뉴얼에 나와 있습니다. 차례차례 보도록 하지요.
첫째, 요청에 필요한 주소는 내려받은 메뉴얼 문서를 참조하는 것이 좋습니다. 공공데이터포털의 오픈API 상세정보 화면에도 ‘요청주소’, ‘서비스URL’ 등 관련 주소가 있지만, 어떤 경우에는 이 주소들이 여러분이 원하는 정보를 요청할 수 있는 주소가 아닌 경우가 있습니다. 그것은 하나의 API가 여러 가지 정보를 주는 경우, 정보의 종류에 따라 조금씩 다른 주소를 사용하기도 하기 때문이죠. 우리가 이용하려는 ‘에어코리아 대기오염정보’ API가 그런 경우입니다. 메뉴얼 문서를 포함하고 있는 압축 파일을 열어보면, 이 API는 ‘대기오염정보’, ‘대기오염통계 현황’, ‘미세먼지 경보 발령 현황’ 등등 여러 종류의 정보를 제공하고 있습니다. 여기서는 그 중 ’대기오염정보’를 이용해볼 것입니다.
‘대기오염정보’를 이용하기 위해서는 해당 메뉴얼을 읽어보아야겠지요. 그러니 압축 파일에 포함된 문서 중, ’한국환경공단_에어코리아_대기오염정보_기술문서_v1.1.docx’파일을 열어봅니다. 스크롤해 내려가다보면, ’대기오염정보 조회 서비스’ 아래 표에 ’Call Back URL’이라는 항목이 있습니다. 주소가 http://apis.data.go.kr/B552584/ArpltnInforInqireSvc/getMsrstnAcctoRltmMesureDnsty로 되어 있네요. 이 주소가 바로 우리가 정보 요청을 위해 사용할 주소 입니다.

둘째, 앞서 ‘에어코리아 대기오염정보’ 이용 승인을 받으면서 개발계정 상세정보에 인증키가 발급되어 있는 것을 확인했습니다.
곧 HTTP를 이용해 API 서버에 정보 요청을 할 때, 정보 요청에 대한 권한을 승인받기 위해 이 인증키를 함께 보낼 것입니다.
셋째, 어떻게 정보를 요청하는데 대한 규칙을 알기 위해서는 다시 메뉴얼로 돌아가야 합니다. 앞서 확인한 ‘Call Back URL’ 바로 아래에 있는 표에 ’요청 메시지 명세’라는 표가 있는데요, 여기서 정보 요청의 규칙을 알 수 있습니다.
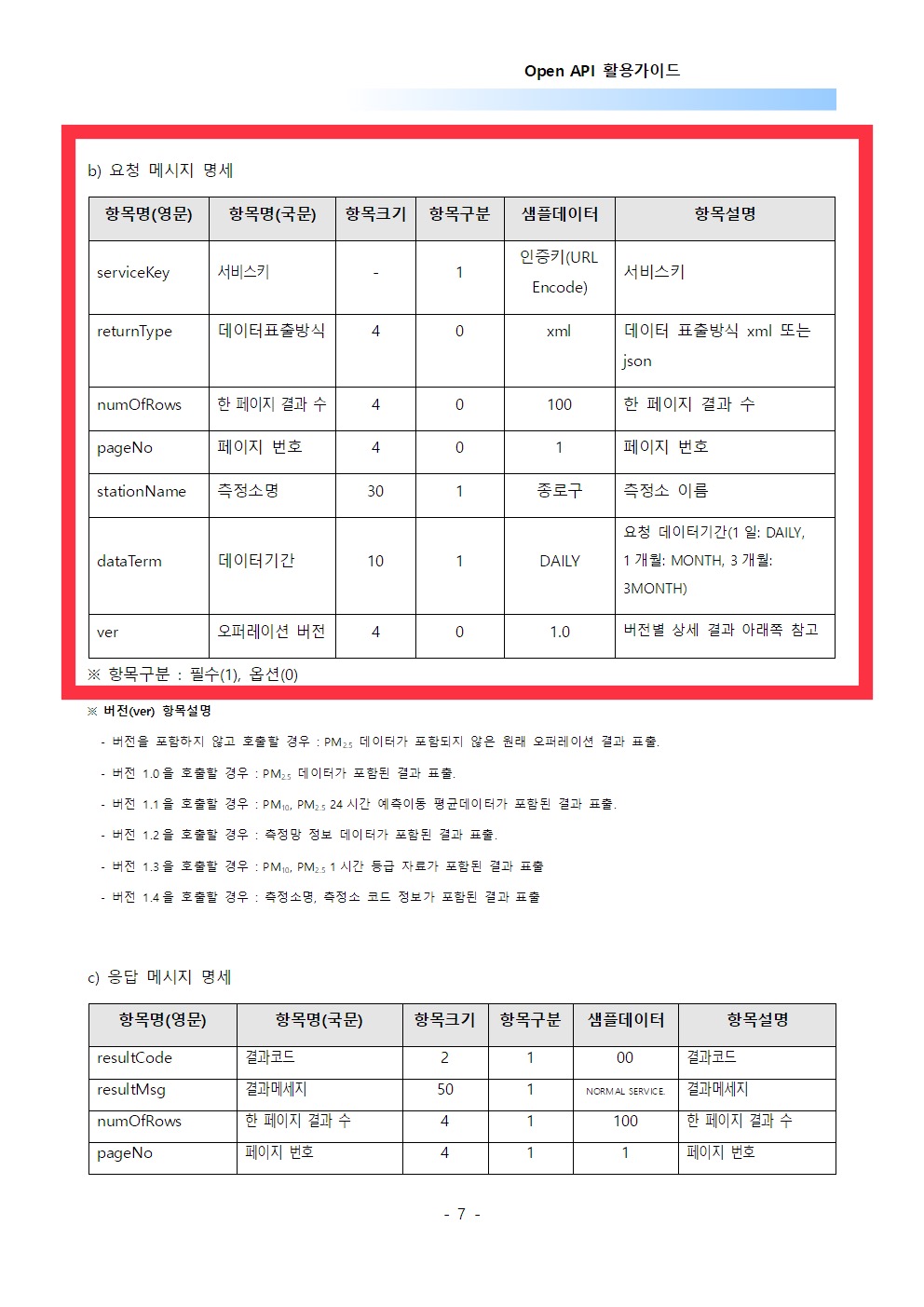
위의 예시에서 보면, 정보를 요청할 때, ‘serviceKey’라는 항목에는 나의 인증키를, ’returnType’이라는 항목에는 json과 xml 중 어떤 데이터 형식으로 정보를 받고 싶은지를, ’numOfRows’라는 항목에는 한 번 요청할 때마다 몇개의 정보를 받고 싶은지를, ’pageNo’ 항목에는 전체 정보 중 몇 번째 페이지에 해당하는 정보를 받고 싶은지를, ’stationName’에는 어느 대기오염 측정소의 정보를 얻고 싶은지를, ’dateTerm’에는 얼마나 긴 기간 동안의 대기오염 정보를 얻고 싶은지를, 마지막으로 지금 당장은 중요하지 않지만 ’ver’에는 제공하는 API의 몇가지 버전 중 어느 것을 이용하고 싶은지를 기입해서 HTTP 메시지로 보내면 된다고 합니다.
사실 모든 항목에 대응하는 메시지를 보내야 하는 것은 아닙니다. serviceKey의 경우에는 내가 권한을 가지고 있다는 것을 밝히기 위해서 꼭 기입해야 하지만, 다른 항목들 중 ’항목구분’이 0이라고 표시되어 있는 경우, 아무 메시지도 보내지 않으면 ’샘플데이터’라는 칼럼에 나와있는 값들이 일종의 디폴트 값으로 가정됩니다. 즉, 이용자가 페이지번호를 넣지 않으면 자동으로 1페이지 정보가 돌아오는 식이지요.
자, 이제 서버에 정보를 요청하기 위한 모든 정보를 알게되었습니다. 이제 R을 이용해 질문만 하면 됩니다. 가장 간단하게 종로구 측정소의 지난 한 달간 대기오염 정보를 원한다고 해 볼까요? 이를 httr 패키지로 요청하면 다음과 같이 됩니다.
res <- GET(url="http://apis.data.go.kr/B552584/ArpltnInforInqireSvc/getMsrstnAcctoRltmMesureDnsty",
query=list(returnType="json",
stationName="종로구",
dataTerm="MONTH",
serviceKey="LGvIXqsO1eCAKjgMBQWd5QYDOJ77cd4Tq/ea2CQUTUuisLvxlxaGm0YTp4f+89FfhplvwiQIe0cngpybTkdDHQ=="))
resResponse [http://apis.data.go.kr/B552584/ArpltnInforInqireSvc/getMsrstnAcctoRltmMesureDnsty?returnType=json&stationName=%EC%A2%85%EB%A1%9C%EA%B5%AC&dataTerm=MONTH&serviceKey=LGvIXqsO1eCAKjgMBQWd5QYDOJ77cd4Tq%2Fea2CQUTUuisLvxlxaGm0YTp4f%2B89FfhplvwiQIe0cngpybTkdDHQ%3D%3D]
Date: 2024-05-07 06:16
Status: 200
Content-Type: application/json;charset=UTF-8
Size: 3.14 kB출력된 결과값 메시지 중 “Status: 200”이라는 표현이 있으면 일단 성공했다고 보아도 좋습니다. 웹API 서버는 종종 네트워크 상태에 따라 반응을 하지 않는 경우도 있으니, 에러 메시지가 보인다고 해서 포기하지 말고 여러 번 시도해 보세요.
정보를 요청하는 위의 코드 그 자체는 그 동안의 설명을 이해했다면 어렵지 않게 이해할 수 있을 것입니다. 먼저 GET() 함수(모두 대문자로 써야 합니다)는 httr 패키지가 제공하는 HTTP 규칙을 이용해 정보 요청을 하기 위한 함수입니다. 앞서 알아낸 서버주소는 GET()함수의 url이라는 인수의 값으로 기입할 수 있습니다. 이제 서버에게 요청할 구체적인 질문은 query라는 인수에 값으로 기입합니다. 단, 이 때는 기입해야 하는 정보가 returnType, stationName, dataTerm, serviceKey 등 여러개 이므로, 이를 list로 묶어서 기입합니다. 아래에서부터 앞서 알아낸 인증키, 그리고 ‘종로구’ 측정소의 ‘한달’ 간 정보를 원한다는 메시지, 그리고 마지막으로 ’json’이라는 데이터 형태로 정보를 보내달라는 요청 내용까지 포함된 것입니다.
이제 res라는 변수에 서버가 보낸 정보가 포함되어 있다는 것은 알지만, 이를 우리가 쓸 수 있는 데이터로 변환하는데에는 몇 가지 작업이 필요합니다. 효율적으로 정보를 주고 받기 위해 기계만 이해할 수 있는 형식을 이용하기 때문이죠. 따라서, 최종 분석을 위해서는 다음과 같은 변환 작업이 필요합니다.
첫번째 변환을 제공하는 함수는 httr 패키지의 content() 함수입니다. 이 함수는 기계가 이해할 수 있느 언어를 사람도 이해할 수 있는 언어로 변환해 줍니다.
dtString <- content(res, "text", encoding="UTF-8")
dtString[1] "{\"response\":{\"body\":{\"totalCount\":719,\"items\":[{\"so2Grade\":\"1\",\"coFlag\":null,\"khaiValue\":\"43\",\"so2Value\":\"0.002\",\"coValue\":\"0.3\",\"pm10Flag\":null,\"pm10Value\":\"8\",\"o3Grade\":\"1\",\"khaiGrade\":\"1\",\"no2Flag\":null,\"no2Grade\":\"1\",\"o3Flag\":null,\"so2Flag\":null,\"dataTime\":\"2024-05-07 15:00\",\"coGrade\":\"1\",\"no2Value\":\"0.012\",\"pm10Grade\":\"1\",\"o3Value\":\"0.026\"},{\"so2Grade\":\"1\",\"coFlag\":null,\"khaiValue\":\"43\",\"so2Value\":\"0.002\",\"coValue\":\"0.3\",\"pm10Flag\":null,\"pm10Value\":\"6\",\"o3Grade\":\"1\",\"khaiGrade\":\"1\",\"no2Flag\":null,\"no2Grade\":\"1\",\"o3Flag\":null,\"so2Flag\":null,\"dataTime\":\"2024-05-07 14:00\",\"coGrade\":\"1\",\"no2Value\":\"0.011\",\"pm10Grade\":\"1\",\"o3Value\":\"0.026\"},{\"so2Grade\":\"1\",\"coFlag\":null,\"khaiValue\":\"40\",\"so2Value\":\"0.002\",\"coValue\":\"0.3\",\"pm10Flag\":null,\"pm10Value\":\"7\",\"o3Grade\":\"1\",\"khaiGrade\":\"1\",\"no2Flag\":null,\"no2Grade\":\"1\",\"o3Flag\":null,\"so2Flag\":null,\"dataTime\":\"2024-05-07 13:00\",\"coGrade\":\"1\",\"no2Value\":\"0.011\",\"pm10Grade\":\"1\",\"o3Value\":\"0.024\"},{\"so2Grade\":\"1\",\"coFlag\":null,\"khaiValue\":\"50\",\"so2Value\":\"0.002\",\"coValue\":\"0.3\",\"pm10Flag\":null,\"pm10Value\":\"6\",\"o3Grade\":\"1\",\"khaiGrade\":\"1\",\"no2Flag\":null,\"no2Grade\":\"1\",\"o3Flag\":null,\"so2Flag\":null,\"dataTime\":\"2024-05-07 12:00\",\"coGrade\":\"1\",\"no2Value\":\"0.010\",\"pm10Grade\":\"1\",\"o3Value\":\"0.025\"},{\"so2Grade\":\"1\",\"coFlag\":null,\"khaiValue\":\"59\",\"so2Value\":\"0.002\",\"coValue\":\"0.3\",\"pm10Flag\":null,\"pm10Value\":\"5\",\"o3Grade\":\"1\",\"khaiGrade\":\"2\",\"no2Flag\":null,\"no2Grade\":\"1\",\"o3Flag\":null,\"so2Flag\":null,\"dataTime\":\"2024-05-07 11:00\",\"coGrade\":\"1\",\"no2Value\":\"0.010\",\"pm10Grade\":\"1\",\"o3Value\":\"0.024\"},{\"so2Grade\":\"1\",\"coFlag\":null,\"khaiValue\":\"69\",\"so2Value\":\"0.002\",\"coValue\":\"0.3\",\"pm10Flag\":null,\"pm10Value\":\"7\",\"o3Grade\":\"1\",\"khaiGrade\":\"2\",\"no2Flag\":null,\"no2Grade\":\"1\",\"o3Flag\":null,\"so2Flag\":null,\"dataTime\":\"2024-05-07 10:00\",\"coGrade\":\"1\",\"no2Value\":\"0.012\",\"pm10Grade\":\"2\",\"o3Value\":\"0.023\"},{\"so2Grade\":\"1\",\"coFlag\":null,\"khaiValue\":\"74\",\"so2Value\":\"0.002\",\"coValue\":\"0.4\",\"pm10Flag\":null,\"pm10Value\":\"36\",\"o3Grade\":\"1\",\"khaiGrade\":\"2\",\"no2Flag\":null,\"no2Grade\":\"1\",\"o3Flag\":null,\"so2Flag\":null,\"dataTime\":\"2024-05-07 09:00\",\"coGrade\":\"1\",\"no2Value\":\"0.014\",\"pm10Grade\":\"2\",\"o3Value\":\"0.028\"},{\"so2Grade\":\"1\",\"coFlag\":null,\"khaiValue\":\"72\",\"so2Value\":\"0.002\",\"coValue\":\"0.5\",\"pm10Flag\":null,\"pm10Value\":\"39\",\"o3Grade\":\"1\",\"khaiGrade\":\"2\",\"no2Flag\":null,\"no2Grade\":\"1\",\"o3Flag\":null,\"so2Flag\":null,\"dataTime\":\"2024-05-07 08:00\",\"coGrade\":\"1\",\"no2Value\":\"0.017\",\"pm10Grade\":\"2\",\"o3Value\":\"0.030\"},{\"so2Grade\":\"1\",\"coFlag\":null,\"khaiValue\":\"69\",\"so2Value\":\"0.002\",\"coValue\":\"0.4\",\"pm10Flag\":null,\"pm10Value\":\"43\",\"o3Grade\":\"2\",\"khaiGrade\":\"2\",\"no2Flag\":null,\"no2Grade\":\"1\",\"o3Flag\":null,\"so2Flag\":null,\"dataTime\":\"2024-05-07 07:00\",\"coGrade\":\"1\",\"no2Value\":\"0.015\",\"pm10Grade\":\"2\",\"o3Value\":\"0.032\"},{\"so2Grade\":\"1\",\"coFlag\":null,\"khaiValue\":\"66\",\"so2Value\":\"0.002\",\"coValue\":\"0.4\",\"pm10Flag\":null,\"pm10Value\":\"46\",\"o3Grade\":\"2\",\"khaiGrade\":\"2\",\"no2Flag\":null,\"no2Grade\":\"1\",\"o3Flag\":null,\"so2Flag\":null,\"dataTime\":\"2024-05-07 06:00\",\"coGrade\":\"1\",\"no2Value\":\"0.012\",\"pm10Grade\":\"2\",\"o3Value\":\"0.035\"}],\"pageNo\":1,\"numOfRows\":10},\"header\":{\"resultMsg\":\"NORMAL_CODE\",\"resultCode\":\"00\"}}}"여기서 “text”는 사람의 언어로 바꾸어 달라는 뜻이고, encoding="UTF-8"은 기계 언어와 사람 언어 사이의 번역 규칙이라고 생각하면 될 것입니다. “UTF-8”는 일반적으로 (들어본 분도 있을 것입니다) “유니코드”라고 부르는 규칙으로, 현대 인터넷의 표준 규칙쯤 됩니다.
출력된 결과는 아직, 알듯, 모를듯 하지요? 이는 사람의 언어로 변환은 되었지만, R이 아직, 이 문자열이 json이라는 특정 형식을 갖는 데이터라는 것을 모르고, 그냥 한 줄로 된 긴 문자열이라고 생각하기 때문입니다. R이 이 문자열을 json 데이터로 이해하기 위해서는 우리가 그 사실을 알려주어야 합니다. 말하자면, ‘네가 지금 보고 있는 문자열이 json 데이터라고 생각하고 다시 한 번 잘 봐봐’ 라고 명령을 내려주는 것이지요.
그러면 json은 어떤 형식의 파일이길래, 편한 테이블 형태의 데이터 형식을 제쳐두고 이를 사용하는 것일까요? 먼저 우리에게 익숙한 테이블 형태의 데이터를 생각해 보면, 우리는 데이터를 테이블로 표현하기 위해서는 열과 행으로 이루어진 2차원 평면 상의 한 칸 한 칸에 값을 집어 넣습니다.
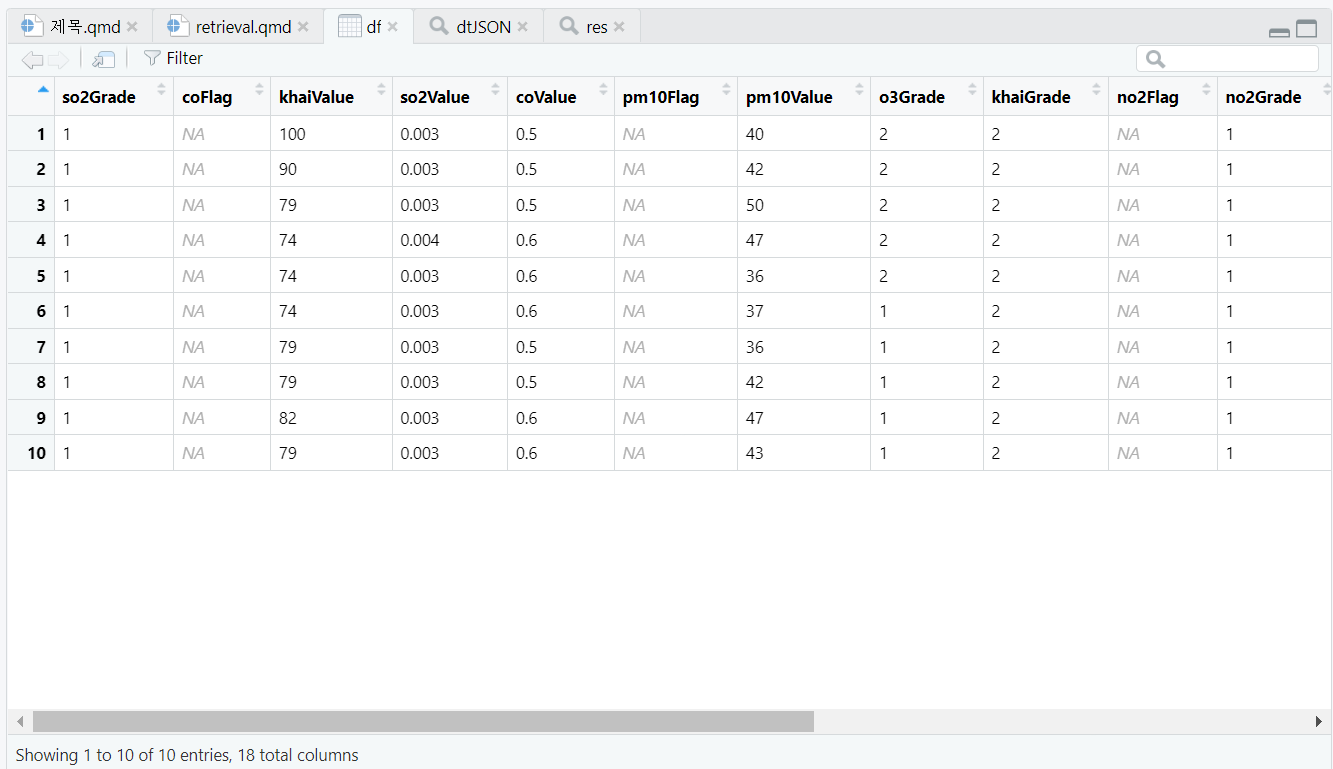
반면에 json은 아주 간단한 나무(tree) 헝태의 데이터 구조 입니다. 즉, 테이블로는 표현 불가능한 값 간의 위계질서, 또는 데이터의 ’깊이’를 표현할 수 있는 것이지요. 방금 받은 데이터를 json이라고 생각하고 표현하면 다음과 같습니다.
이제 R에게 문자열을 json으로 이해해 보라고 말하기 위해서는 jsonlite 패키지의 fromJSON()이라는 함수를 사용할 것입니다.
library(jsonlite)Warning: package 'jsonlite' was built under R version 4.3.3
Attaching package: 'jsonlite'The following object is masked from 'package:purrr':
flattendtJSON <- fromJSON(dtString)
dtJSON$response
$response$body
$response$body$totalCount
[1] 719
$response$body$items
so2Grade coFlag khaiValue so2Value coValue pm10Flag pm10Value o3Grade
1 1 NA 43 0.002 0.3 NA 8 1
2 1 NA 43 0.002 0.3 NA 6 1
3 1 NA 40 0.002 0.3 NA 7 1
4 1 NA 50 0.002 0.3 NA 6 1
5 1 NA 59 0.002 0.3 NA 5 1
6 1 NA 69 0.002 0.3 NA 7 1
7 1 NA 74 0.002 0.4 NA 36 1
8 1 NA 72 0.002 0.5 NA 39 1
9 1 NA 69 0.002 0.4 NA 43 2
10 1 NA 66 0.002 0.4 NA 46 2
khaiGrade no2Flag no2Grade o3Flag so2Flag dataTime coGrade no2Value
1 1 NA 1 NA NA 2024-05-07 15:00 1 0.012
2 1 NA 1 NA NA 2024-05-07 14:00 1 0.011
3 1 NA 1 NA NA 2024-05-07 13:00 1 0.011
4 1 NA 1 NA NA 2024-05-07 12:00 1 0.010
5 2 NA 1 NA NA 2024-05-07 11:00 1 0.010
6 2 NA 1 NA NA 2024-05-07 10:00 1 0.012
7 2 NA 1 NA NA 2024-05-07 09:00 1 0.014
8 2 NA 1 NA NA 2024-05-07 08:00 1 0.017
9 2 NA 1 NA NA 2024-05-07 07:00 1 0.015
10 2 NA 1 NA NA 2024-05-07 06:00 1 0.012
pm10Grade o3Value
1 1 0.026
2 1 0.026
3 1 0.024
4 1 0.025
5 1 0.024
6 2 0.023
7 2 0.028
8 2 0.030
9 2 0.032
10 2 0.035
$response$body$pageNo
[1] 1
$response$body$numOfRows
[1] 10
$response$header
$response$header$resultMsg
[1] "NORMAL_CODE"
$response$header$resultCode
[1] "00"이제 R은 dtJSON이 json 형태의 데이터였다는 것을 이해하고, 이를 스스로 다룰 수 있는 형태로 변환했습니다. 사실 json은 인터넷 통신을 위해 주로 사용하는 데이터 형식이지, R 고유의 형식은 아닙니다. 그런데, R에는 json은 아니지만, json과 같이 나무 형태의 데이터 구조를 처리할 수 있는 데이터 형식이 있습니다. 그것은 바로 list이지ㅛ. 따라서, fromJSON() 함수는 주어진 json데이터의 구조를 이해하면 이를 바로 R의 list 형식으로 변환합니다. 이제 Rstudio의 오른쪽 ‘Envrionment’ 상태창에 있는 dtJSON 항목을 클릭해보면 다음과 같은 화면이 나타날 것입니다.
str(dtJSON)List of 1
$ response:List of 2
..$ body :List of 4
.. ..$ totalCount: int 719
.. ..$ items :'data.frame': 10 obs. of 18 variables:
.. .. ..$ so2Grade : chr [1:10] "1" "1" "1" "1" ...
.. .. ..$ coFlag : logi [1:10] NA NA NA NA NA NA ...
.. .. ..$ khaiValue: chr [1:10] "43" "43" "40" "50" ...
.. .. ..$ so2Value : chr [1:10] "0.002" "0.002" "0.002" "0.002" ...
.. .. ..$ coValue : chr [1:10] "0.3" "0.3" "0.3" "0.3" ...
.. .. ..$ pm10Flag : logi [1:10] NA NA NA NA NA NA ...
.. .. ..$ pm10Value: chr [1:10] "8" "6" "7" "6" ...
.. .. ..$ o3Grade : chr [1:10] "1" "1" "1" "1" ...
.. .. ..$ khaiGrade: chr [1:10] "1" "1" "1" "1" ...
.. .. ..$ no2Flag : logi [1:10] NA NA NA NA NA NA ...
.. .. ..$ no2Grade : chr [1:10] "1" "1" "1" "1" ...
.. .. ..$ o3Flag : logi [1:10] NA NA NA NA NA NA ...
.. .. ..$ so2Flag : logi [1:10] NA NA NA NA NA NA ...
.. .. ..$ dataTime : chr [1:10] "2024-05-07 15:00" "2024-05-07 14:00" "2024-05-07 13:00" "2024-05-07 12:00" ...
.. .. ..$ coGrade : chr [1:10] "1" "1" "1" "1" ...
.. .. ..$ no2Value : chr [1:10] "0.012" "0.011" "0.011" "0.010" ...
.. .. ..$ pm10Grade: chr [1:10] "1" "1" "1" "1" ...
.. .. ..$ o3Value : chr [1:10] "0.026" "0.026" "0.024" "0.025" ...
.. ..$ pageNo : int 1
.. ..$ numOfRows : int 10
..$ header:List of 2
.. ..$ resultMsg : chr "NORMAL_CODE"
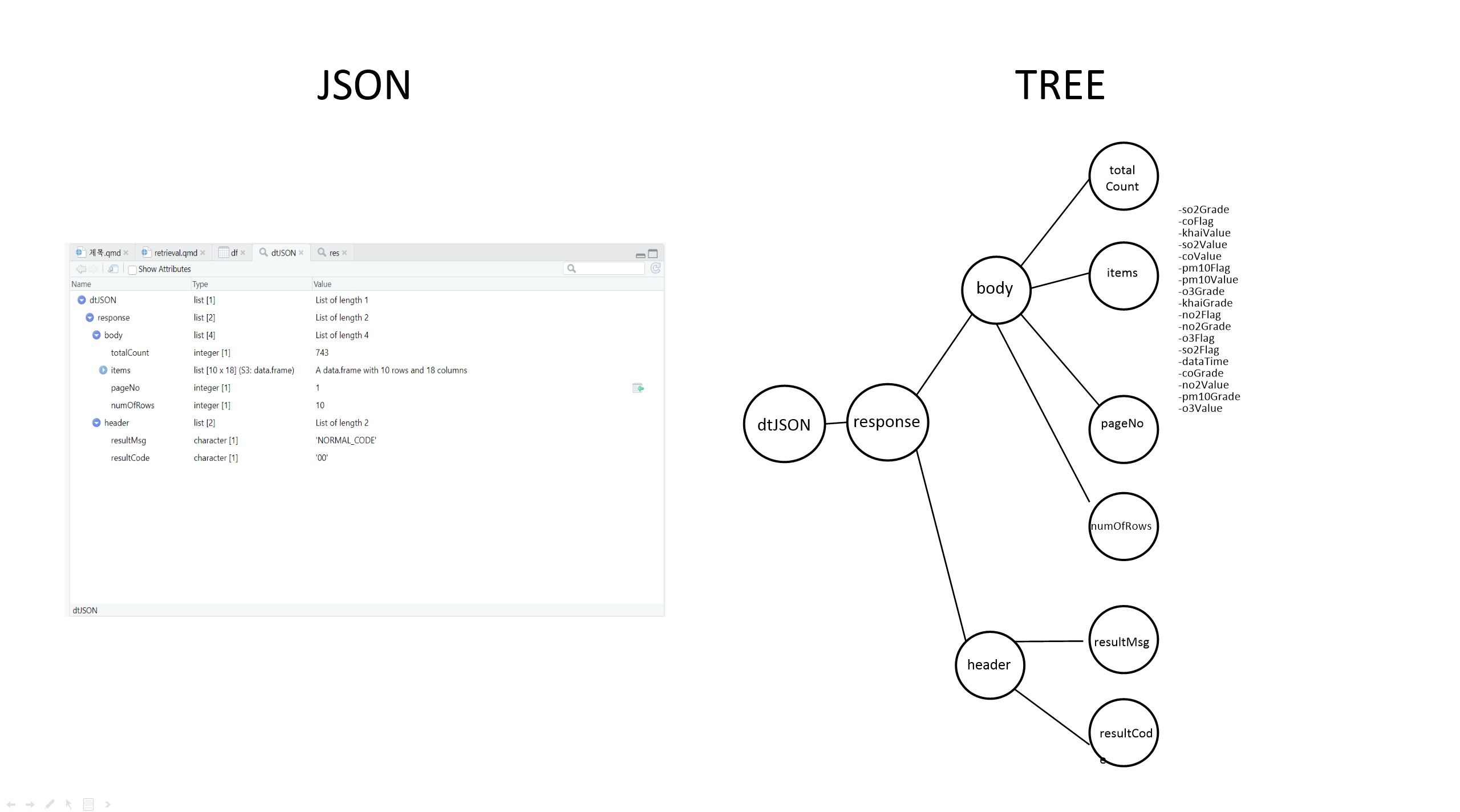
.. ..$ resultCode: chr "00"여기서 보이는 데이터 구조를 그림으로 그리면, 다음과 같이 나무 가지와 같은 형태가 됩니다.
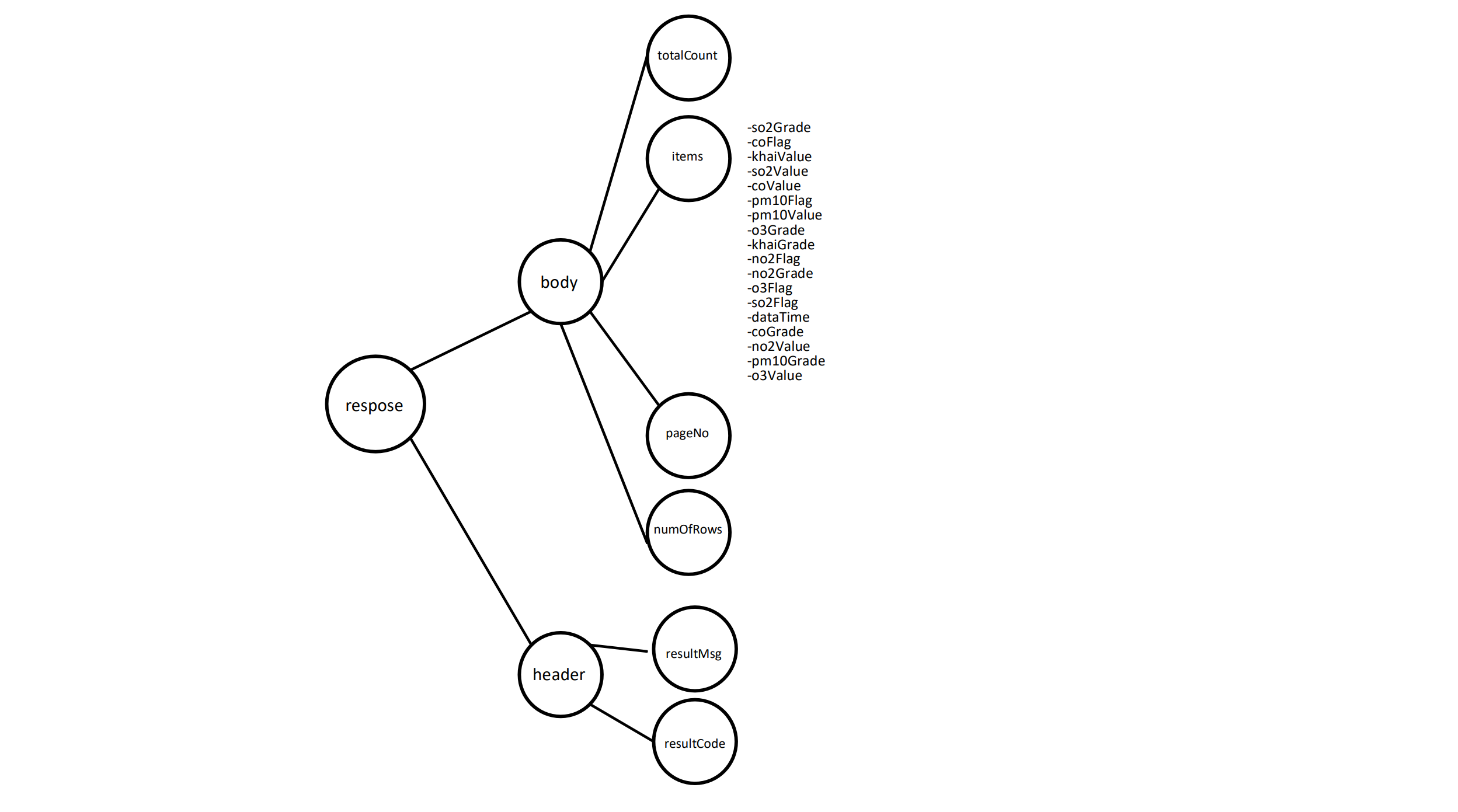
웹API가 우리에게 익숙한 테이블 형태의 데이터를 이용하지 않고, json과 같이 생소한 데이터 타입을 이용하는 이유는 바로 이와 같은 가지치기 구조가 통신에는 더욱 편리한 경우가 많기 때문입니다.
위의 그림에서 또 한 가지 알 수 있는 것은 우리가 정말 필요로 하는 테이블(즉 ‘data.frame’)은 ’dtJSON-response-body-items’에 숨어 있다는 것입니다. R은 json 형식의 파일을 이미 R 고유의 list 형식으로 변환했으니, 우리가 앞서 list의 서브세팅에서 배웠듯이 다음과 같은 명령문을 이용해 이 테이블에 접근할 수 있습니다.
df <- dtJSON$response$body$items
df so2Grade coFlag khaiValue so2Value coValue pm10Flag pm10Value o3Grade
1 1 NA 43 0.002 0.3 NA 8 1
2 1 NA 43 0.002 0.3 NA 6 1
3 1 NA 40 0.002 0.3 NA 7 1
4 1 NA 50 0.002 0.3 NA 6 1
5 1 NA 59 0.002 0.3 NA 5 1
6 1 NA 69 0.002 0.3 NA 7 1
7 1 NA 74 0.002 0.4 NA 36 1
8 1 NA 72 0.002 0.5 NA 39 1
9 1 NA 69 0.002 0.4 NA 43 2
10 1 NA 66 0.002 0.4 NA 46 2
khaiGrade no2Flag no2Grade o3Flag so2Flag dataTime coGrade no2Value
1 1 NA 1 NA NA 2024-05-07 15:00 1 0.012
2 1 NA 1 NA NA 2024-05-07 14:00 1 0.011
3 1 NA 1 NA NA 2024-05-07 13:00 1 0.011
4 1 NA 1 NA NA 2024-05-07 12:00 1 0.010
5 2 NA 1 NA NA 2024-05-07 11:00 1 0.010
6 2 NA 1 NA NA 2024-05-07 10:00 1 0.012
7 2 NA 1 NA NA 2024-05-07 09:00 1 0.014
8 2 NA 1 NA NA 2024-05-07 08:00 1 0.017
9 2 NA 1 NA NA 2024-05-07 07:00 1 0.015
10 2 NA 1 NA NA 2024-05-07 06:00 1 0.012
pm10Grade o3Value
1 1 0.026
2 1 0.026
3 1 0.024
4 1 0.025
5 1 0.024
6 2 0.023
7 2 0.028
8 2 0.030
9 2 0.032
10 2 0.035드디어 우리가 원하는 테이블을 얻을 수 있었습니다!
11.4 XML 데이터의 요청 및 처리 (고급)
이번에는 json이 아니라, XML 형태의 데이터를 API로부터 받았을 경우에 대해서 살펴보겠습니다. XML도 json처럼 나무 형태에 데이터를 표현하기 위한 구조이지만, 표현하는 방법이 조금 더 복잡하고, 테이블 형태로 변환하는 법도 조금 더 복잡합니다. 하지만, 어떤 API는 데이터를 XML 형태로만 제공하는 경우도 있으니, 살펴보고 넘어가도록 하지요. XML이 json과 어떻게 다른지는 곧 보게될 예를 통해 쉽게 이해할 수 있을 것입니다.
먼저 XML데이터를 R에서 쉽게 다루기 위해서는 다음 두 패키지를 이용하는 것이 좋습니다.
library(xml2)
library(purrr)이제 앞서 사용한 것과 동일한 대기오염 데이터를 GET() 함수를 이용해 받아보겠습니다. 모든 것이 똑같지만, returnType에 투입된 인수가 ’json’이 아니라 ’xml’이라는 것만 다르다는 것을 알 수 있습니다. 이 때문에 이제 API는 데이터를 XML형태로 보내주게 되지요.
res <- GET(url="http://apis.data.go.kr/B552584/ArpltnInforInqireSvc/getMsrstnAcctoRltmMesureDnsty",
query=list(returnType="xml",
stationName="종로구",
dataTerm="MONTH",
serviceKey="LGvIXqsO1eCAKjgMBQWd5QYDOJ77cd4Tq/ea2CQUTUuisLvxlxaGm0YTp4f+89FfhplvwiQIe0cngpybTkdDHQ=="))
resResponse [http://apis.data.go.kr/B552584/ArpltnInforInqireSvc/getMsrstnAcctoRltmMesureDnsty?returnType=xml&stationName=%EC%A2%85%EB%A1%9C%EA%B5%AC&dataTerm=MONTH&serviceKey=LGvIXqsO1eCAKjgMBQWd5QYDOJ77cd4Tq%2Fea2CQUTUuisLvxlxaGm0YTp4f%2B89FfhplvwiQIe0cngpybTkdDHQ%3D%3D]
Date: 2024-05-07 06:16
Status: 200
Content-Type: application/xml;charset=UTF-8
Size: 5.83 kB
<BINARY BODY>앞서의 경우와 마찬가지로, 결과에 포함된 Status Code가 200이면 정상적으로 데이터가 도착한 것입니다. 그런 다음, 도착한 데이터를 사람이 읽을 수 있는 문자열로 변환하는 과정도 동일합니다.
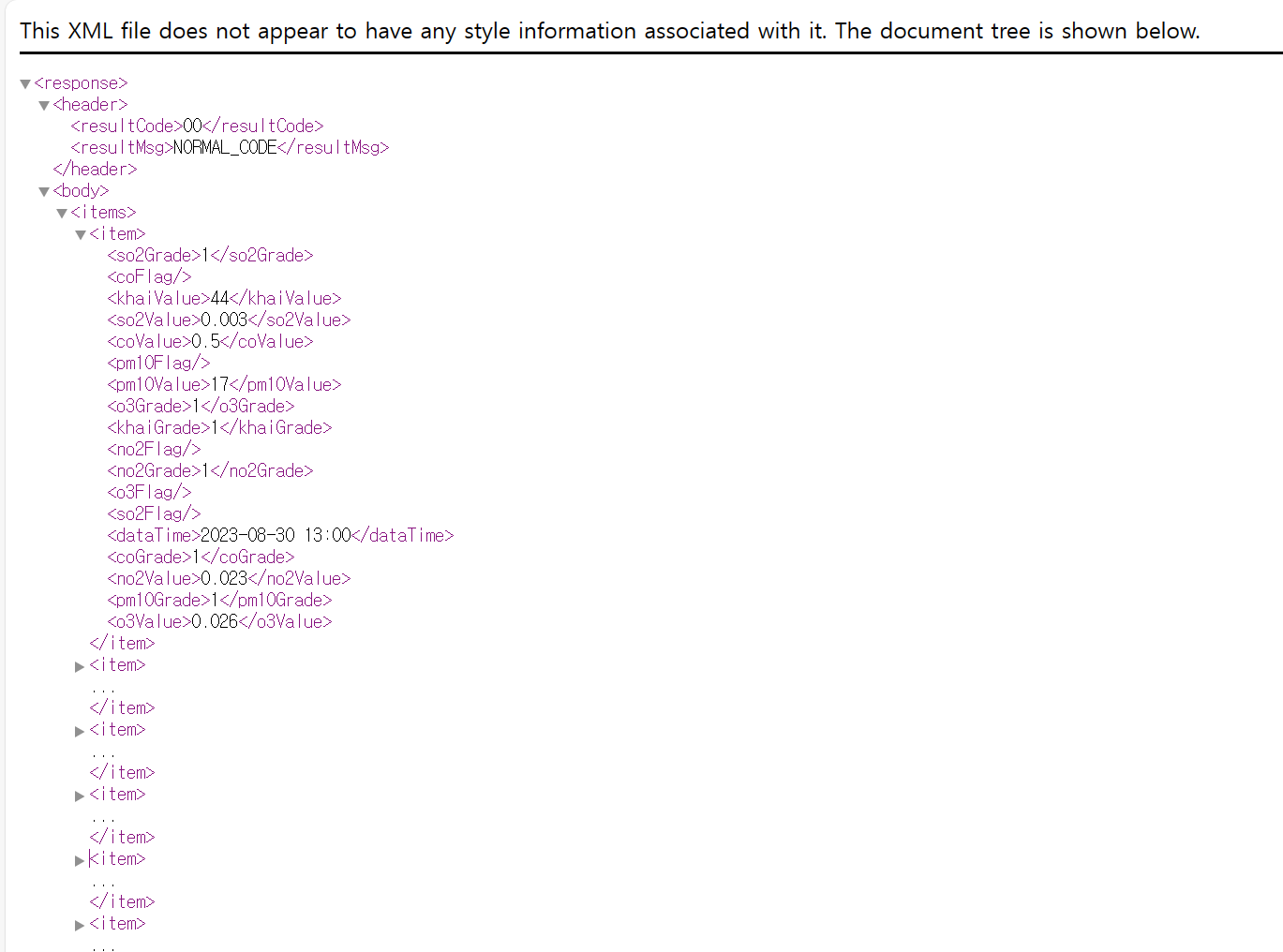
dtXMLstring <- content(res, "text", encoding="UTF-8")
dtXMLstring[1] "<?xml version=\"1.0\" encoding=\"UTF-8\"?>\r\n<response>\n <header>\n <resultCode>00</resultCode>\n <resultMsg>NORMAL_CODE</resultMsg>\n </header>\n <body>\n <items>\n <item>\n <so2Grade>1</so2Grade>\n <coFlag/>\n <khaiValue>43</khaiValue>\n <so2Value>0.002</so2Value>\n <coValue>0.3</coValue>\n <pm10Flag/>\n <pm10Value>8</pm10Value>\n <o3Grade>1</o3Grade>\n <khaiGrade>1</khaiGrade>\n <no2Flag/>\n <no2Grade>1</no2Grade>\n <o3Flag/>\n <so2Flag/>\n <dataTime>2024-05-07 15:00</dataTime>\n <coGrade>1</coGrade>\n <no2Value>0.012</no2Value>\n <pm10Grade>1</pm10Grade>\n <o3Value>0.026</o3Value>\n </item>\n <item>\n <so2Grade>1</so2Grade>\n <coFlag/>\n <khaiValue>43</khaiValue>\n <so2Value>0.002</so2Value>\n <coValue>0.3</coValue>\n <pm10Flag/>\n <pm10Value>6</pm10Value>\n <o3Grade>1</o3Grade>\n <khaiGrade>1</khaiGrade>\n <no2Flag/>\n <no2Grade>1</no2Grade>\n <o3Flag/>\n <so2Flag/>\n <dataTime>2024-05-07 14:00</dataTime>\n <coGrade>1</coGrade>\n <no2Value>0.011</no2Value>\n <pm10Grade>1</pm10Grade>\n <o3Value>0.026</o3Value>\n </item>\n <item>\n <so2Grade>1</so2Grade>\n <coFlag/>\n <khaiValue>40</khaiValue>\n <so2Value>0.002</so2Value>\n <coValue>0.3</coValue>\n <pm10Flag/>\n <pm10Value>7</pm10Value>\n <o3Grade>1</o3Grade>\n <khaiGrade>1</khaiGrade>\n <no2Flag/>\n <no2Grade>1</no2Grade>\n <o3Flag/>\n <so2Flag/>\n <dataTime>2024-05-07 13:00</dataTime>\n <coGrade>1</coGrade>\n <no2Value>0.011</no2Value>\n <pm10Grade>1</pm10Grade>\n <o3Value>0.024</o3Value>\n </item>\n <item>\n <so2Grade>1</so2Grade>\n <coFlag/>\n <khaiValue>50</khaiValue>\n <so2Value>0.002</so2Value>\n <coValue>0.3</coValue>\n <pm10Flag/>\n <pm10Value>6</pm10Value>\n <o3Grade>1</o3Grade>\n <khaiGrade>1</khaiGrade>\n <no2Flag/>\n <no2Grade>1</no2Grade>\n <o3Flag/>\n <so2Flag/>\n <dataTime>2024-05-07 12:00</dataTime>\n <coGrade>1</coGrade>\n <no2Value>0.010</no2Value>\n <pm10Grade>1</pm10Grade>\n <o3Value>0.025</o3Value>\n </item>\n <item>\n <so2Grade>1</so2Grade>\n <coFlag/>\n <khaiValue>59</khaiValue>\n <so2Value>0.002</so2Value>\n <coValue>0.3</coValue>\n <pm10Flag/>\n <pm10Value>5</pm10Value>\n <o3Grade>1</o3Grade>\n <khaiGrade>2</khaiGrade>\n <no2Flag/>\n <no2Grade>1</no2Grade>\n <o3Flag/>\n <so2Flag/>\n <dataTime>2024-05-07 11:00</dataTime>\n <coGrade>1</coGrade>\n <no2Value>0.010</no2Value>\n <pm10Grade>1</pm10Grade>\n <o3Value>0.024</o3Value>\n </item>\n <item>\n <so2Grade>1</so2Grade>\n <coFlag/>\n <khaiValue>69</khaiValue>\n <so2Value>0.002</so2Value>\n <coValue>0.3</coValue>\n <pm10Flag/>\n <pm10Value>7</pm10Value>\n <o3Grade>1</o3Grade>\n <khaiGrade>2</khaiGrade>\n <no2Flag/>\n <no2Grade>1</no2Grade>\n <o3Flag/>\n <so2Flag/>\n <dataTime>2024-05-07 10:00</dataTime>\n <coGrade>1</coGrade>\n <no2Value>0.012</no2Value>\n <pm10Grade>2</pm10Grade>\n <o3Value>0.023</o3Value>\n </item>\n <item>\n <so2Grade>1</so2Grade>\n <coFlag/>\n <khaiValue>74</khaiValue>\n <so2Value>0.002</so2Value>\n <coValue>0.4</coValue>\n <pm10Flag/>\n <pm10Value>36</pm10Value>\n <o3Grade>1</o3Grade>\n <khaiGrade>2</khaiGrade>\n <no2Flag/>\n <no2Grade>1</no2Grade>\n <o3Flag/>\n <so2Flag/>\n <dataTime>2024-05-07 09:00</dataTime>\n <coGrade>1</coGrade>\n <no2Value>0.014</no2Value>\n <pm10Grade>2</pm10Grade>\n <o3Value>0.028</o3Value>\n </item>\n <item>\n <so2Grade>1</so2Grade>\n <coFlag/>\n <khaiValue>72</khaiValue>\n <so2Value>0.002</so2Value>\n <coValue>0.5</coValue>\n <pm10Flag/>\n <pm10Value>39</pm10Value>\n <o3Grade>1</o3Grade>\n <khaiGrade>2</khaiGrade>\n <no2Flag/>\n <no2Grade>1</no2Grade>\n <o3Flag/>\n <so2Flag/>\n <dataTime>2024-05-07 08:00</dataTime>\n <coGrade>1</coGrade>\n <no2Value>0.017</no2Value>\n <pm10Grade>2</pm10Grade>\n <o3Value>0.030</o3Value>\n </item>\n <item>\n <so2Grade>1</so2Grade>\n <coFlag/>\n <khaiValue>69</khaiValue>\n <so2Value>0.002</so2Value>\n <coValue>0.4</coValue>\n <pm10Flag/>\n <pm10Value>43</pm10Value>\n <o3Grade>2</o3Grade>\n <khaiGrade>2</khaiGrade>\n <no2Flag/>\n <no2Grade>1</no2Grade>\n <o3Flag/>\n <so2Flag/>\n <dataTime>2024-05-07 07:00</dataTime>\n <coGrade>1</coGrade>\n <no2Value>0.015</no2Value>\n <pm10Grade>2</pm10Grade>\n <o3Value>0.032</o3Value>\n </item>\n <item>\n <so2Grade>1</so2Grade>\n <coFlag/>\n <khaiValue>66</khaiValue>\n <so2Value>0.002</so2Value>\n <coValue>0.4</coValue>\n <pm10Flag/>\n <pm10Value>46</pm10Value>\n <o3Grade>2</o3Grade>\n <khaiGrade>2</khaiGrade>\n <no2Flag/>\n <no2Grade>1</no2Grade>\n <o3Flag/>\n <so2Flag/>\n <dataTime>2024-05-07 06:00</dataTime>\n <coGrade>1</coGrade>\n <no2Value>0.012</no2Value>\n <pm10Grade>2</pm10Grade>\n <o3Value>0.035</o3Value>\n </item>\n </items>\n <numOfRows>10</numOfRows>\n <pageNo>1</pageNo>\n <totalCount>719</totalCount>\n </body>\n</response>"그런데 결과물이 더 복잡하게 생겼지요? 아직 R은 이 문자열이 XML 데이터라는 것을 알기 전인데, 우리는 XML 데이터라는 것을 알고 있으니, 이를 미리 그림으로 표현해 보면 다음과 같습니다.
XML이 복잡해 보이는 이유는 json과 달리, 변수 정보를 표현하는 형식이 값의 앞 뒤에 붙어있다는 것입니다. 이게 무슨 말인가 하면, 다음 그림과 같이 json은 값 앞에 한 번 변수 이름을 표시해 주지만, XML의 경우에는 값 뒤에도 변수 이름을 표시해 준다는 것입니다.
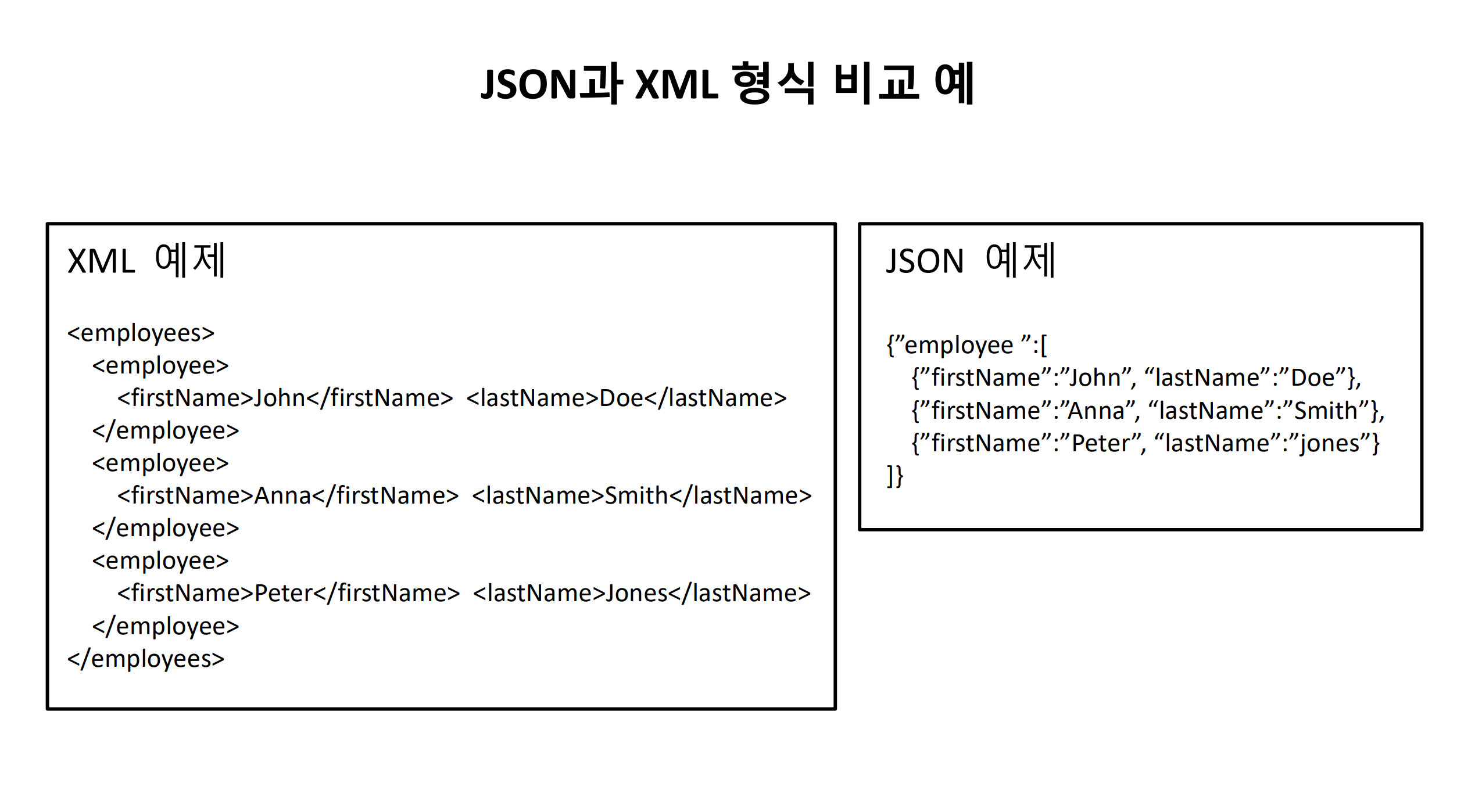
그 외에는 XML도 json처럼 나무 형식의 데이터를 표현하는 하나의 방식에 줄과합니다. 이제 json에 대해서 그랬던 것처럼, R에게 방금 본 문자열이 사실은 XML이었다고 말해줄 차례입니다. 이렇게 말해주기 위한 xml2 패키지의 함수는 read_xml 입니다.
dtXML <- dtXMLstring |>
read_xml() |>
as_list() 그런데 read_xml() 뒤에 as_list()라는 다른 함수가 쓰였죠? 이는 read_xml() 함수가 jsonlite의 fromJSON() 함수와 달리 XML 데이터를 바로 R의 list 데이터로 변환하지 않기 때문입니다. list로 변환하지 않고 데이터를 다루는 방법도 있지만, 이는 다소 까다롭기 때문에 역시 xml2 패키지에 포함된 함수인 as_list() 함수를 이용해 list로 변환까지 하기로 하겠습니다.
이제 Rstudio 화면 우측 상단에 있는 ‘Environment’ 창에서 dtXML을 클릭하여 데이터 구조를 보도록 합시다.
.png)
우리가 원하는 대기 오염 대이터는 ‘response’ 아래 ‘body’ 아래 ‘items’ 아래 열개의 ’item’으로 표현되어 있다는 것을 알 수 있습니다. 그리고 각각의 item은 또 다시 다음과 같은 나무 형태이지요.
우리가 이를 테이블로 변환하려면, item 하나를 테이블을 한 행(row)으로 item 안에 있는 각각의 값을 하나의 열(column)로 표현해야 합니다. 문제는 R이 반대의 경우, 즉, 각각의 item이 열이고, 그 안에 있는 요소들이 행인 상황에는 테이블로 만드는 것은 쉽게 하지만, 이 경우는 조금 에둘러가야 한다는 것입니다. 이를 해결하기 위해서는 여러 방법이 있지만, 제일 간단한 방법은 주어진 list의 구조를 반대로 먼저 만들어주는 것입니다. 즉, 다음과 같이 만들어 주는 것이지요.
![]()
이를 위한 함수는 아까 불러온 purrr 패키지의 transpose() 함수 입니다.
dtXML_transposed <- dtXML$response$body$items |>
transpose()이제 새로 만들어진 dtXML_transposed의 구조를 Environment 패널에서 확인해 보세요. 위의 그림처럼 바뀌어져 있을 것입니다. 그런다음 테이블로 바꾸어주면 됩니다.
dfXML <- dtXML$response$body$items |>
transpose() |>
as_tibble() |>
unnest(cols=everything(), keep_empty = TRUE) 그런데 transpose() 뒤에도 여전히 알쏭달쏭한 코드들이 붙어있지요? 그 이유는 ’transpose’한 후 테이블로 만들어 주어도 각각의 대기오염 측정치가 원 데이터의 구조상 단순한 값이 아니라, 값이 한 개 있는 작은 리스트로 변환되기 때문입니다. 비유해서 말하자면, 우리는 과일 하나하나가 필요한데, 과일과 과일이 메달린 가지 하나가 같이 왔다고 할 수 있습니다.
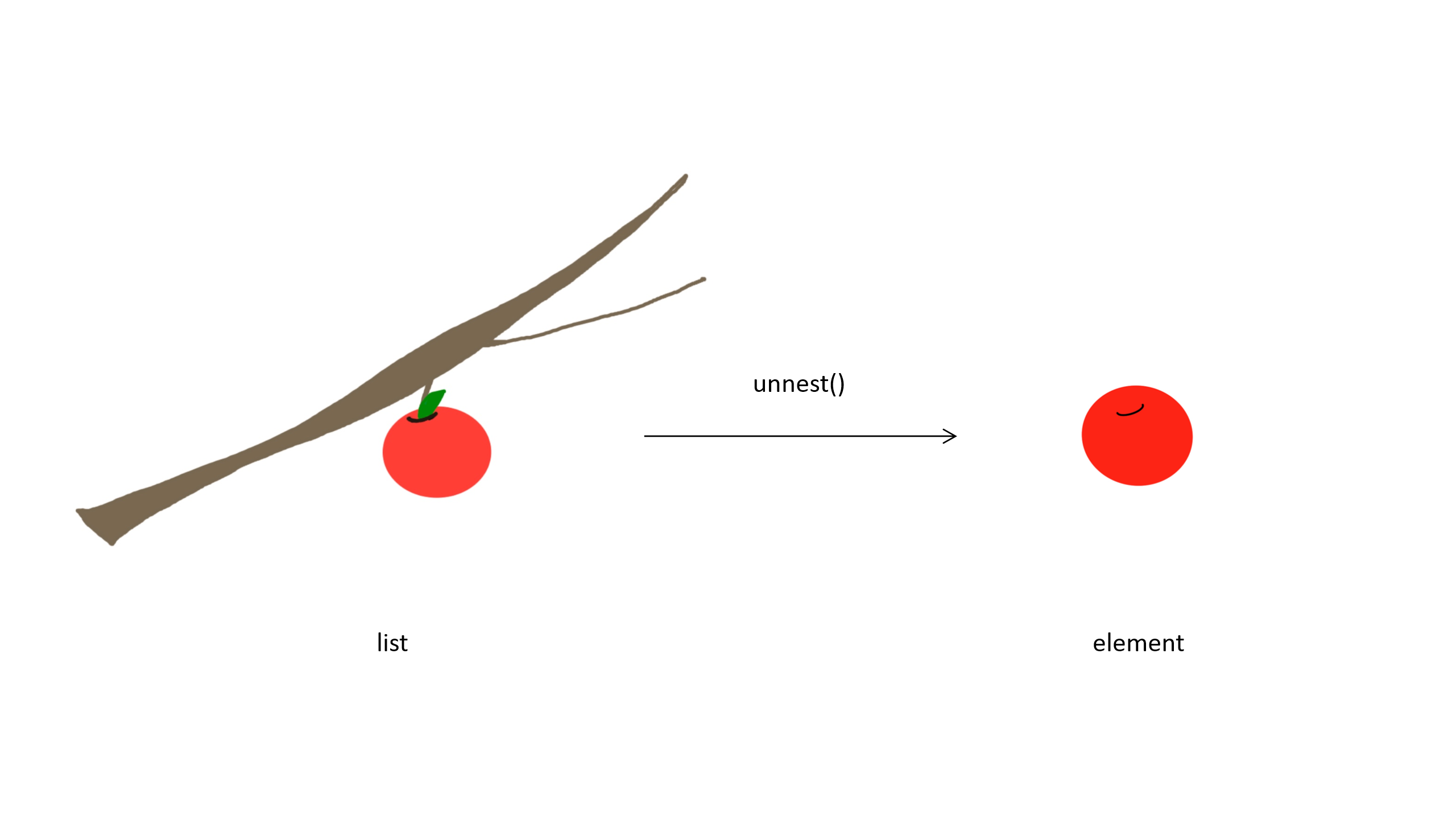
이런 문제를 다루기 위해 일반 데이터 프레임과 매우 비슷하지만 조금 더 유연한 기능을 가진 테이블 형식을 tidyverse가 제공하는데, 이를 tibble이라고 부릅니다. 데이터 프레임은 각 칸에 과일 하나만 넣을 수 있지만, tibble은 가지가 달린 과일로 넣을 수 있다고 생각해 보세요. 그래서 데이터 프레임으로 만들지 않고 as_tibble() 함수를 이용해 tibble로 만들었습니다. 해당 함수 역시 tidyverse 패키지에 속해있지요. 이제 이렇게 만들어진 tibble의 모든 칸에는 가지 끝에 달린 과일이 (즉, 각각의 값이 리스트 형태로) 들어있습니다.
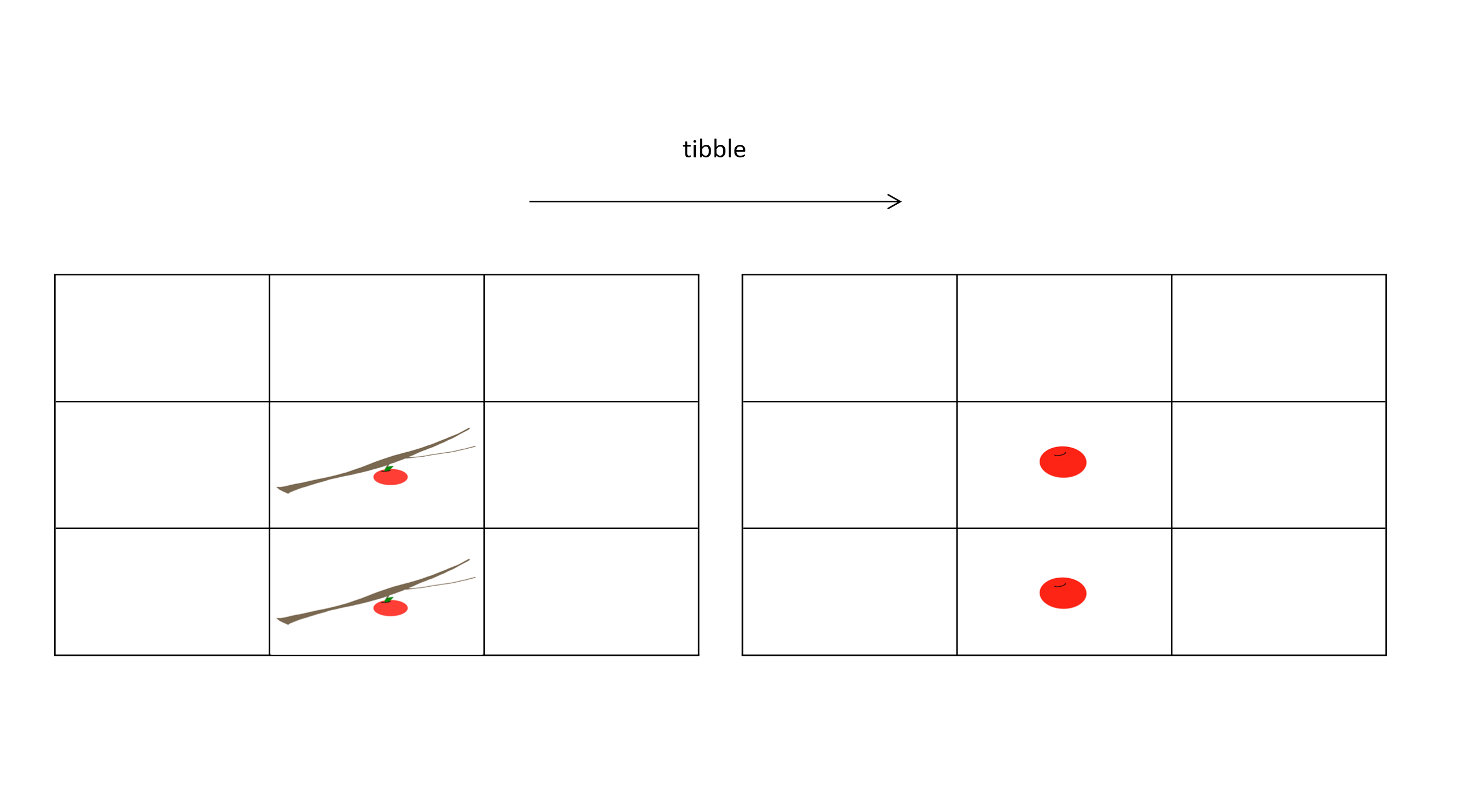
이제 모든 칸에서 가지를 떼주어야 합니다. 그래야 과일에 해당하는 값들을 사용할 수 있거든요. 이 작업은 tidyverse의 unnest() 함수를 통해 할 수 있습니다. 그 안의 인수는 다음과 같은 뜻 압니다.
cols=everything(): 모든 열(column)을unnest()할 것.keep_empty=TRUE: 값이 없는 칸, 비어 있는대로 둘 것.
이제 위의 코드를 실행하고, Envrionment 패널에서 dfXML을 클릭해보세요. 아까 json 데이터를 처리해서 보았던 것과 동일한 테이블을 획득했다는 것을 알 수 있습니다.
보신 바와 같이 XML 파일은 그 후속 작업이 조금 복잡합니다. json 형태의 데이터를 받을 수 있다면 json을 선택하는 것이 아무래도 효율적이겠지요.
11.5 웹스크레이핑 기초: HTML 기초
앞서 이야기한 것처럼, 데이터를 보유한 측에서 따로 API를 제공하지 않는다면, 웹페이지로 부터 데이터를 직접 가져오는 방법을 생각해볼 수 있습니다. 물론 데이터의 양이 적다면, 브라우저에 표시된 테이블을 드레그 해서 복사-붙여넣기 하는 것도 방법이겠지만, 그렇게 손으로 작업하기에는 데이터의 양이 지나치게 많은 경우도 있지요. 이 때는 프로그래밍을 통해 복사-붙여넣기 작업을 컴퓨터가 자동으로 하도록 시키는 것을 고려해볼 수 있겠지요. 이를 웹스크레이핑이라고 합니다. 만약, 어디에 어떤 정보가 있는지를 자동으로 찾아가면서 동시에 복사-붙여넣기를 해야하는 더 고약한 작업은 웹크롤링이라고 부르지요. 스크레이핑과 크롤링은 API를 이용할 때와 달리 데이터 형태가 표준화되어 있지 않고, 해당 웹사이트가 어떻게 작동하는지를 거꾸로 역추적해야 하는 경우가 대부분이기 때문에, 여기서 다루기에는 상당히 방대한 양의 많은 지식과 기술을 필요로 합니다. 하지만, 비교적 간단한 형태의 웹사이트, 구체적으로 ’정적웹(Static Web)’이라고 부르는 웹사이트의 경우에는 R을 통해 간단한 스크레이핑 작업을 할 수 있습니다. 이 교재에서는 그러한 경우만 다루고, 그 이상을 위해서는 어떤 추가 지식이 필요한지만 짧게 언급하고 넘어가도록 하겠습니다.
R에서 가장 간단하게 웹스크레이핑을 하는 방법은 rvest라는 패키지를 이용하는 것입니다. 먼저 패키지를 설치하도록 합시다.
install.packages('rvest')패키지 사용을 위해서 물론 패키지를 로드해야겠지요.
library(rvest)
Attaching package: 'rvest'The following object is masked from 'package:readr':
guess_encoding간단한 예시를 위해 2023년 TV방영 드라마에 대한 정보를 찾는다고 해 보지요. 특히 드라마 작가, 연출자, 제작사 등의 정보 같은 경우에는 하나하나 조사를 하는 것보다 팬들이 모아놓은 정보가 상당히 충실한 경우가 많습니다(물론 정확성은 사후 검증해야 한다는 것은 두말 할 나위 없겠지요). 찾아보니 위키피디아에 2022년_대한민국의_텔레비전_드라마_목록이라는 항목이 있네요.
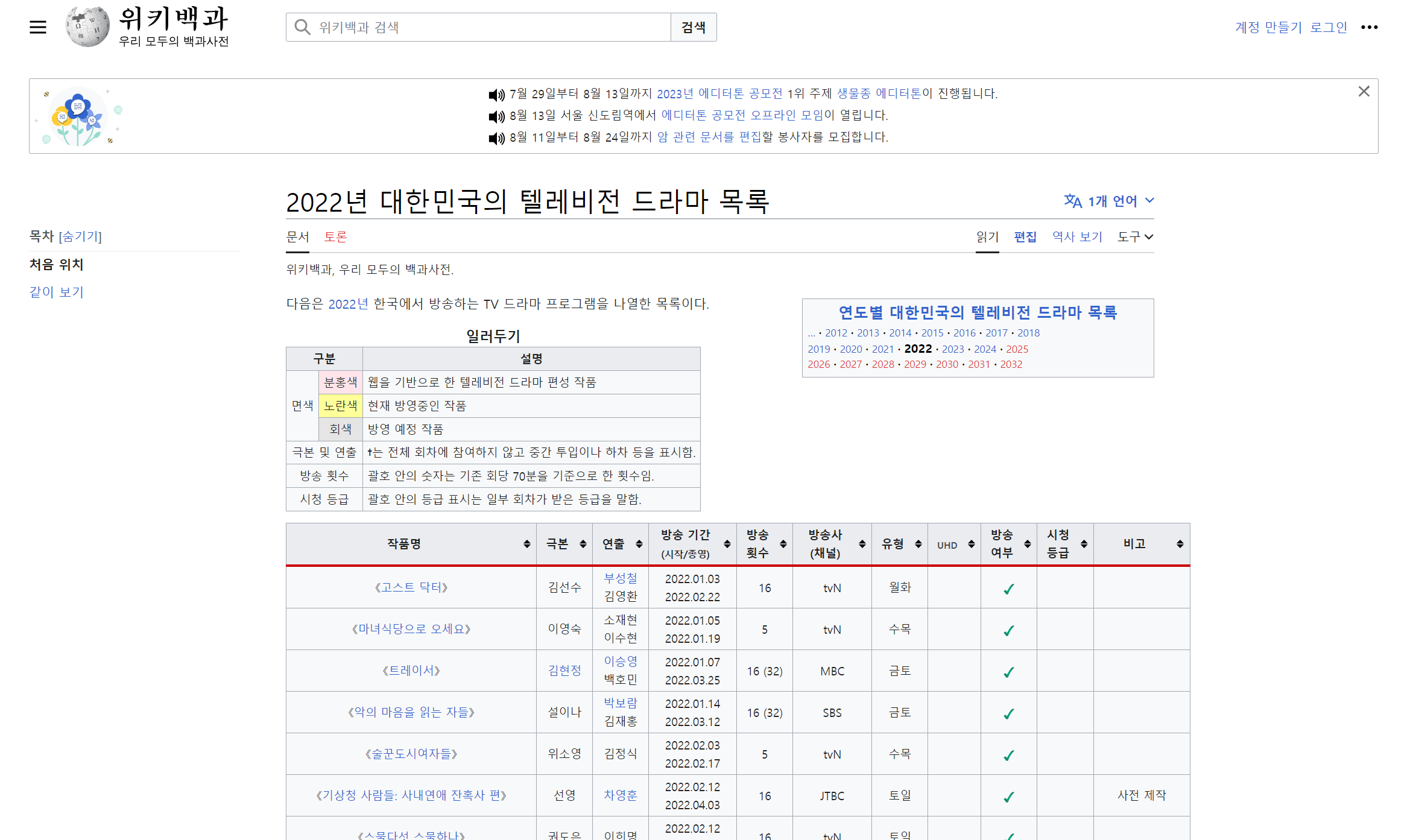
여기에 큰 테이블이 있으니, 이 정보를 복사해 오도록 R에게 지시하면 되겠습니다. 그런데, 스크레이핑을 위해서는 HTML 이라는 웹 문서 표준에 대한 기초적인 이해가 조금 필요합니다. 아마, 여러분들도 인터넷을 사용하시면서 HTML이라는 용어는 여러번 들어보셨을 것입니다. HTML은 HyperText Markup Language의 줄임말로, 웹페이지를 작성하는 문서 표준 입니다. HTML 규칙에 따라 문서를 작성하면 여러분이 사용하시는 크롬, 엣지 등의 웹브라우저가 이를 이해하고 여러분들에게 익숙한 알록달록한 웹페이지로 표현해서 보여주는 것이지요. 즉, 여러분이 웹브라우저 주소 창에 URL 주소를 치고 엔터를 누르면, 여러분의 컴퓨터(클라이언트라고도 부릅니다)와 웹사이트 서버가 정보를 주고 받는데, 이 때 서버가 보내는 정보가 바로 HTML 파일 이라고 생각하시면 되겠습니다. 그리고 여러분 컴퓨터의 브라우저가 이를 웹페이지로 번역해서 보여주는 것이고요.

위의 그림에서 보듯이 이렇게 웹서버와 클라이언트 간에 HTML을 주고 받을 때 사용하는 통신 규칙이 API를 사용하면서도 이야기했던 HTTP이고요.
우리가 브라우저를 통해 보는 웹페이지는 화려하지만, 브라우저가 해석하기 전의 HTML 파일 자체는 특정 규칙을 따르는 문서 파일에 불과합니다. 웹스크레이핑은 이 규칙을 역이용해서 컴퓨터가 원하는 정보를 찾도록 하는 작업이라고 보아도 무방합니다. 그러면 가장 간다한 HTML 파일 형태를 볼까요?
<html>
<head> </head>
<body>
<h1> 이것은 제목 입니다 </h1>
<p> 이것은 문단 입니다 </p>
</body>
</html>앞에서 본 xml 파일과 거의 동일한 형태를 가지고 있지요? 사실 xml과 html은 친척 관계라고 할 수 있습니다. html은 xml처럼 정보의 앞 뒤에 붙은 테그를 이용해서 텍스트에 추가적인 정보를 덧붙입니다.
는 그 사이에 들어오는 텍스트가 문서의 본문에 해당함을,
는 그 사이의 텍스트가 하나의 문단임을 표현하는 식이지요. HTML은 다양한 정보를 덧붙이기 위해서 여러가지 tag를 가지고 있습니다. 이를 잘 이용하면 컴퓨터에게 ‘이 HTML 문서에 있는 모든 제목을 복사해 줘’, 또는 ‘이 HTML 문서에 있는 모든 본문 문단을 복사해 줘’ 같은 요청을 할 수 있겠지요.
드라마 목록 사례에서는 해당 문서에 있는 큰 표를 복사해 오면 되는데, HTML은 표를 나타내는
테그가 있습니다. 물론 우리가 웹브라우저에서 해당 위키피디아 페이지를 보았을 때, 큰 표를 볼 수 있는 것은 브라우저가 HTML 문서의 테이블 테그를 이해하고 표로 해석해 주었기 때문이지요.
그러면 우리는 R에게 ’이 HTML 문서에 있는 모든 테이블을 복사해 줘’라고 요청하면 되겠군요. rvest 패키지를 이용해 이런 요청을 할 때는 다음과 같이 하면 됩니다.
url <- 'https://ko.wikipedia.org/wiki/2022%EB%85%84_%EB%8C%80%ED%95%9C%EB%AF%BC%EA%B5%AD%EC%9D%98_%ED%85%94%EB%A0%88%EB%B9%84%EC%A0%84_%EB%93%9C%EB%9D%BC%EB%A7%88_%EB%AA%A9%EB%A1%9D'
tables <- url |>
read_html() |>
html_table()
Sys.setlocale("LC_ALL", "korean")Warning in Sys.setlocale("LC_ALL", "korean"): using locale code page other than
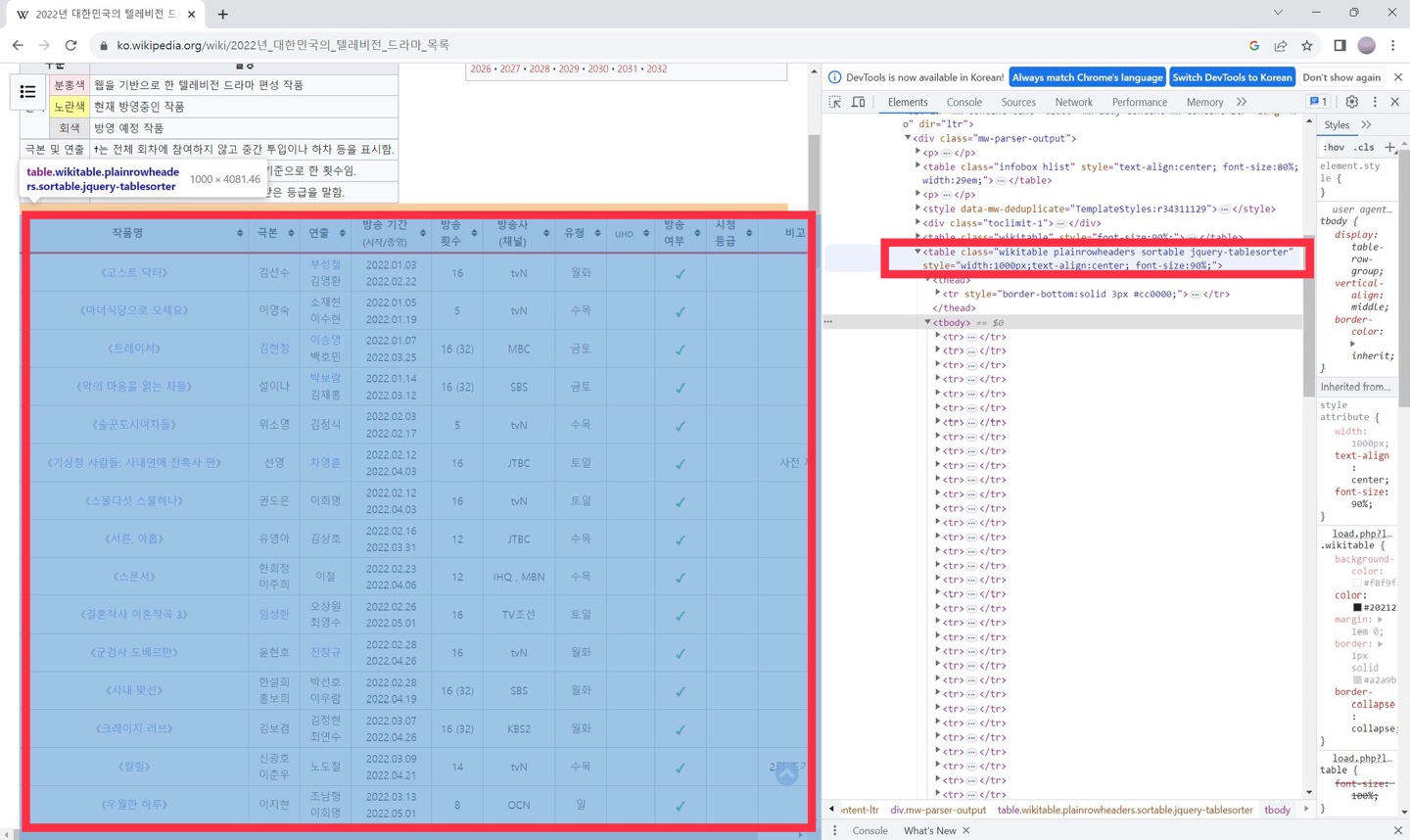
65001 ("UTF-8") may cause problems[1] "LC_COLLATE=Korean_Korea.949;LC_CTYPE=Korean_Korea.949;LC_MONETARY=Korean_Korea.949;LC_NUMERIC=C;LC_TIME=Korean_Korea.949"str(tables)List of 3
$ : tibble [1 x 1] (S3: tbl_df/tbl/data.frame)
..$ 연도별 대한민국의 텔레비전 드라마 목록: chr ".mw-parser-output .hlist dl,.mw-parser-output .hlist ol,.mw-parser-output .hlist ul{margin:0;padding:0}.mw-pars"| __truncated__
$ : tibble [4 x 2] (S3: tbl_df/tbl/data.frame)
..$ 구분: chr [1:4] "분홍색" "극본 및 연출" "방송 횟수" "시청 등급"
..$ 설명: chr [1:4] "면색이 분홍색일 경우 웹을 기반으로 한 텔레비전 드라마 편성 작품" "‘†’는 전체 회차에 참여하지 않고 중간 투입이나 하차 등을 표시함." "괄호 안의 숫자는 기존 회당 70분을 기준으로 한 횟수임." "괄호 안의 등급 표시는 일부 회차가 받은 등급을 말함."
$ : tibble [85 x 11] (S3: tbl_df/tbl/data.frame)
..$ 작품명 : chr [1:85] "《고스트 닥터》" "《마녀식당으로 오세요》" "《트레이서》" "《악의 마음을 읽는 자들》" ...
..$ 극본 : chr [1:85] "김선수" "이영숙" "김현정" "설이나" ...
..$ 연출 : chr [1:85] "부성철김영환" "소재현이수현" "이승영백호민" "박보람김재홍" ...
..$ 방송 기간(시작/종영): chr [1:85] "2022.01.032022.02.22" "2022.01.052022.01.19" "2022.01.072022.03.25" "2022.01.142022.03.12" ...
..$ 방송횟수 : chr [1:85] "16" "5" "16 (32)" "16 (32)" ...
..$ 방송사(채널) : chr [1:85] "tvN" "tvN" "MBC" "SBS" ...
..$ 유형 : chr [1:85] "월화" "수목" "금토" "금토" ...
..$ UHD : logi [1:85] NA NA NA NA NA NA ...
..$ 방송여부 : chr [1:85] "예" "예" "예" "예" ...
..$ 시청등급 : logi [1:85] NA NA NA NA NA NA ...
..$ 비고 : chr [1:85] "" "" "" "" ...첫줄은 우리가 스크레이핑을 하려고 하는 URL의 주소 입니다. 실제로 저 주소를 웹브라우저 주소창에 치고 검색을 해 보면 다음과 같은 한글 주소라는 것을 알 수 있습니다.
https://ko.wikipedia.org/wiki/2022년_대한민국의_텔레비전_드라마_목록
그런데, 웹의 설계상 URL은 흔히 ASCII 부호라고 불리는 아주 기본적인 알파벳과 숫자, 아주 한정된 특수문자들로만 구성되도록 되어 있습니다. 하지만, 지금 우리가 사용하는 URL에서도 그렇듯, 최근에는 URL에 한글 또는 다른 문자를 자유롭게 활용하기도 하는데요, 이를 실제로 인터넷 통신에 활용할 때는 이를 ASCII 부호로 모두 변환해 주어야 하는 것이지요. 이를 ‘URL인코딩’ 이라고 하며, URL 인코딩은 통신에 적합한 알파벳 또는 숫자로 원래 문자를 바꾸어 주는 것이므로, 앞서 이야기 했던 문자를 컴퓨터가 저장할 수 있는 기계어로 바꾸어주는 인코딩과는 조금 다른 개념입니다. 아무튼, 위의 복잡한 URL은 그렇게 인코딩된 주소라고 생각하면 될 것입니다.
그 다음, 해당 url을 rvest 패키지의 read_html() 함수에 집어넣으면, 해당 웹페이지를 웹브라우저가 개입하기 전에 원래 HTML 형태로 그대로 복사해 오게 됩니다. 복잡한 HTML 문서에서 테이블 부분 (즉,
테그에 둘러싸인 부분)만을 가져오는 함수가 html_table()인 것입니다. 그 결과를 tables라는 변수에 저장시켰습니다.
그 다음 Sys.setlocale("LC_ALL", "korean")은 R의 문자 환경을 바꾸어 주는 옵션인데요, 웹에서 복사해 온 데이터가 한글로 되어 있음을 알려주는 것이라는 정도로 이해하면 좋겠습니다.
위의 str(tables)의 결과를 보면 tables는 3개의 테이블로 구성된 리스트라는 것을 알 수 있습니다. 그것은 우리가 스크레이핑 하려고 했던 페이지에 사실은 테이블이 3개 있었기 때문입니다. 우리가 관심을 가지고 있는 큰 테이블 말고도, 아래에서 보는 것처럼, ‘일러두기’ 부분 역시 테이블로 되어 있습니다.
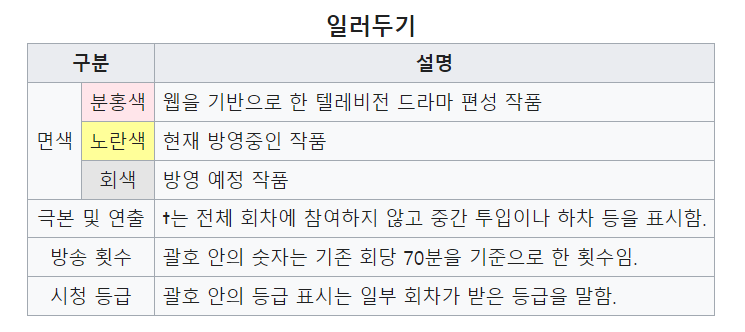
우리가 스크레이핑 하려고 했던 테이블은 3번째 테이블로 저장이 되어 있으니, 다음과 같이 원하는 부분을 서브세팅 해 주면 최종 결과를 얻을 수 있습니다.
drama2023 <- tables[[3]]
drama2023# A tibble: 85 x 11
작품명 극본 연출 `방송 기간(시작/종영)` 방송횟수 `방송사(채널)` 유형 UHD
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <lgl>
1 《고~ 김선~ 부성~ 2022.01.032022.02.22 16 tvN 월화 NA
2 《마~ 이영~ 소재~ 2022.01.052022.01.19 5 tvN 수목 NA
3 《트~ 김현~ 이승~ 2022.01.072022.03.25 16 (32) MBC 금토 NA
4 《악~ 설이~ 박보~ 2022.01.142022.03.12 16 (32) SBS 금토 NA
5 《술~ 위소~ 김정~ 2022.02.032022.02.17 5 tvN 수목 NA
6 《기~ 선영 차영~ 2022.02.122022.04.03 16 JTBC 토일 NA
7 《스~ 권도~ 이희~ 2022.02.122022.04.03 16 tvN 토일 NA
8 《서~ 유영~ 김상~ 2022.02.162022.03.31 12 JTBC 수목 NA
9 《스~ 한희~ 이철 2022.02.232022.04.06 12 IHQ , MBN 수목 NA
10 《결~ 임성~ 오상~ 2022.02.262022.05.01 16 TV조선 토일 NA
# i 75 more rows
# i 3 more variables: 방송여부 <chr>, 시청등급 <lgl>, 비고 <chr>11.6 고급 스크레이핑을 위한 조언
사실 이렇게 간단한 작업을 위해서 스크레이핑까지 동원할 필요는 없습니다. 위의 예라면, 마우스로 원하는 표를 드래그 해서 엑셀에 붙여넣기를 할 수도 있을 테고, 최악의 경우 표에 있는 정보 하나하나를 손으로 옮겨 적는다고 해도 한 시간이 채 걸리지는 않을 것 같습니다. 하지만, 만약 위키피디아에 1960년대부터 이런 표가 한 해 당 하나씩 있고, 이를 모두 분석에 이용하고 싶다면 어떻게 해야 할까요? 각 페이지의 URL 주소만 알면 위의 작업을 반복해 주면 되겠지요. 이를 위해서 R 프로그램 뿐만 아니라, 모든 프로그래밍 언어의 근간이라고 할 수 있는 ’반복문’과 위의 코드를 섞어 써 주면 됩니다.
원하는 정보가 테이블 형태로 되어 있지 않다면 어떻게 해야 할까요? 그 때는 HTML에 포함된 <table> </table> 이외의 다양한 테그들을 선택해 주면 됩니다. 예컨대 ’해당 웹페이지에 있는 세 번째
테그의 문장을 복사해줘’ 같은 구체적인 지시를 할 수 있습니다. 이를 위해서는 rvest의 html_node(), html_text() 함수와 함께 xpath 또는 CSS selector라는 다른 툴을 같이 써 주어야 합니다. 이들은 어디에 있는 어떤 테그를 원한다는 것을 말해주기 위해 필요한 언어라고 이해하시면 되겠습니다.
rvest는 앞서 우리가 ’정적 웹(Static Web)’이라고 부른 상대적으로 단순한 구조의 웹페이지를 스크레이핑 하기 위한 도구입니다. 정적 웹에서는 URL 주소를 웹브라우저에 치면, HTTP 규약을 이용해 한 번 HTML 문서를 주고 받으면 다음 URL을 이용한 요청이 있을 때까지 통신이 이루어지지 않는다고 했지요? 하지만, 조금 더 복잡한 웹페이지는 웹페이지가 브라우저에서 표현되고 난 이후에도 통신이 완전히 끊기지 않습니다. 예컨대, 구글맵 같은 것을 사용할 때, 마우스 휠을 움직이면 지도의 크기가 변하지요? 이는 서버와 여러분의 브라우저 사이에 계속해서 여러분의 행동을 데이터로 주고 받고 있기 때문입니다. 이러한 웹페이지를 ’동적 웹(dynamic Web)’이라고 합니다.
이렇게 동적 웹으로 디자인된 웹피이지에서 정보를 스크레이핑 할 때는 rvest의 기능으로 역부족인 경우가 상당히 많이 있습니다. 그 때에는 R이 웹브라우저의 힘을 빌려야 합니다. 구체적으로, R이 가상의 웹브라우저를 열어서 여러분이 직접 웹서치를 하는 것과 거의 동일한 행동을 모사하도록 해 주어야 합니다. 이 때 쓰는 라이브러리로 Selenium이라는 유명한 프로그램이 있습니다. 이 프로그램은 사실 R과 독립적으로 개발된 프로그램이기 때문에 R에서 사용할 수도 있지만 파이썬과 같은 다른 언어와 함께 사용할 수도 있습니다. 이 정도까지 오게 되면 상당힌 많은 기술을 필요로 하기 때문에, 여러분이 직접 모든 스크레이핑 과정을 디자인 하기 보다는 전문가와 협업을 하시는 것을 추천합니다.
스크레이핑을 넘어서, 어디에 어떤 정보가 있는지부터 찾아내야 하는 경우, 즉 ’웹 크롤링’을 해야 하는 경우에는 Rcrawler라는 패키지를 활용할 수 있습니다. 하지만, 크롤링 같은 복잡한 작업을 하기 위해서는 R이 꼭 최적의 프로그램이라고 하기는 어렵습니다. 이 역시 전문가와 협업을 통해 접근하시기를 권합니다.